
I attended Blaine Bettinger’s DNA class entitled “Adding Shared Matches and Genetic Networks to Your Research” today (Thursday) at RootsTech 2019. I’m excited to share my notes with you.
Description
Shared matching and genetic clusters are among some of the most powerful tools genealogists have to work with DNA evidence. We will look at some company and third-party tools that allow us to use these powerful networks!
About Blaine
Blaine Bettinger, Ph.D., J.D., is a professional genealogist specializing in DNA evidence, and founder of DNA Central (www.DNA-Central.com), a membership portal for DNA education. He is the author of The Family Tree Guide to DNA Testing and Genetic Genealogy, as well as Genetic Genealogy in Practice (with Debbie Parker Wayne). His genealogy journey began in 1988, and he added DNA to that journey in 2003.
Notes on Genetic Networks
Blaine did an amazing job explaining genetic networks. It was exactly what I needed to learn in my journey to utilize more DNA evidence in my research. I’m excited to share my notes below.
What are they?
I got to the class a few minutes late, so I’m going to share Blaine’s excellent description of genetic networks from the syllbaus: “A genetic network is an arranged cluster of individuals that have taken a genealogy DNA test, arranged in a group that allows the identification of new information from the grouping. Genetic networks are created using: (1) shared matching information; (2) shared segment information; or (3) both.”
How do we form them?
Ancestry DNA Custom Groups
AncestryDNA now allows you to create your own genetic clusters. You simply select a match and select “add to group.” Then you choose a color for the custom group. There are 24 colors to choose from! Blaine says that he creates a hypothesis, then starts adding people to a custom research group. He titled one of his example groups the “Sofia Hernandez Research group.” His hypothesis is that all the people he has added to this group have shared ancestry. He’s trying to figure out he’s related to Sofia Hernandez. He found the list of people to add to this group by going to his match, Sofia Hernandez, then clicking “shared matches.” Then he sees all of the group.
The benefit of this is being able to create up to 24 research groups that are saved in you Ancestry account. This helps you stay organized and remember what you’ve been working on. It’s sort of like a research log for DNA matches.
What’s the purpose of creating this research group when you could just click on Sofia’s shared matches? Chances are you are not going to solve this right away and you are going to have to come back to this over time. You can always see who you did and did not enter. It’s clear to see when a new shared match comes in!
Shared Matches at FamilyTree DNA
Click the box next to a match, then click “in common with.” This shows you the matches shared with the individual you checked. Now you have a genetic cluster. There is no easy way to create a grouping here.
Shared Matches at MyHeritage DNA
Click review DNA match and you ‘ll see the list of matches you have in common. This showed Blaine a list of shared matches, including his mother. Now he knows this match is from is mother’s side. MyHeritage shows how much DNA you share with your matches. But how do you see how much DNA your shared matches share with each other? You can only get this extra piece of information about shared matches and how much DNA they share with each other is from MyHeritage and 23andMe.
MyHeritage is bringing together shared match clustering with chromosome matching. It shows how you, a match, and a shared match, all share a certain piece of DNA. The ultimate tool Blaine wants is a tool that does all of this and layers everything. (Blaine is amazing at coming up with tools and then getting them created!)
Genetic Affairs
This is a genetic networking tool that works with 23andMe, AncestryDNA, or FTDNA (and now MyHeritage!). You can bring in kits that you have tested with other companies and click “autocluster.” This goes to get the information and create clusters, and send the results to you by email.
Each analysis is 25 credits or $0.25. You can change the thresholds for how many cM to include in the cluster. You should test different levels because it depends on how many people who have tested from your close relatives. You may not want to see all your first cousins in your cluster, so lower your threshold so you don’t see all those close relatives. After you do the analysis, you get an email from Genetic Affairs, and one of the attachments is “auto-clustering.” Save to your desktop, then open it. The .html file opens in a browser and you get a cluster graph and a cluster table (with links to the matches and imported notes).
The chart shows 10 clusters. Each one of the colored boxes is a new cluster for your to research.
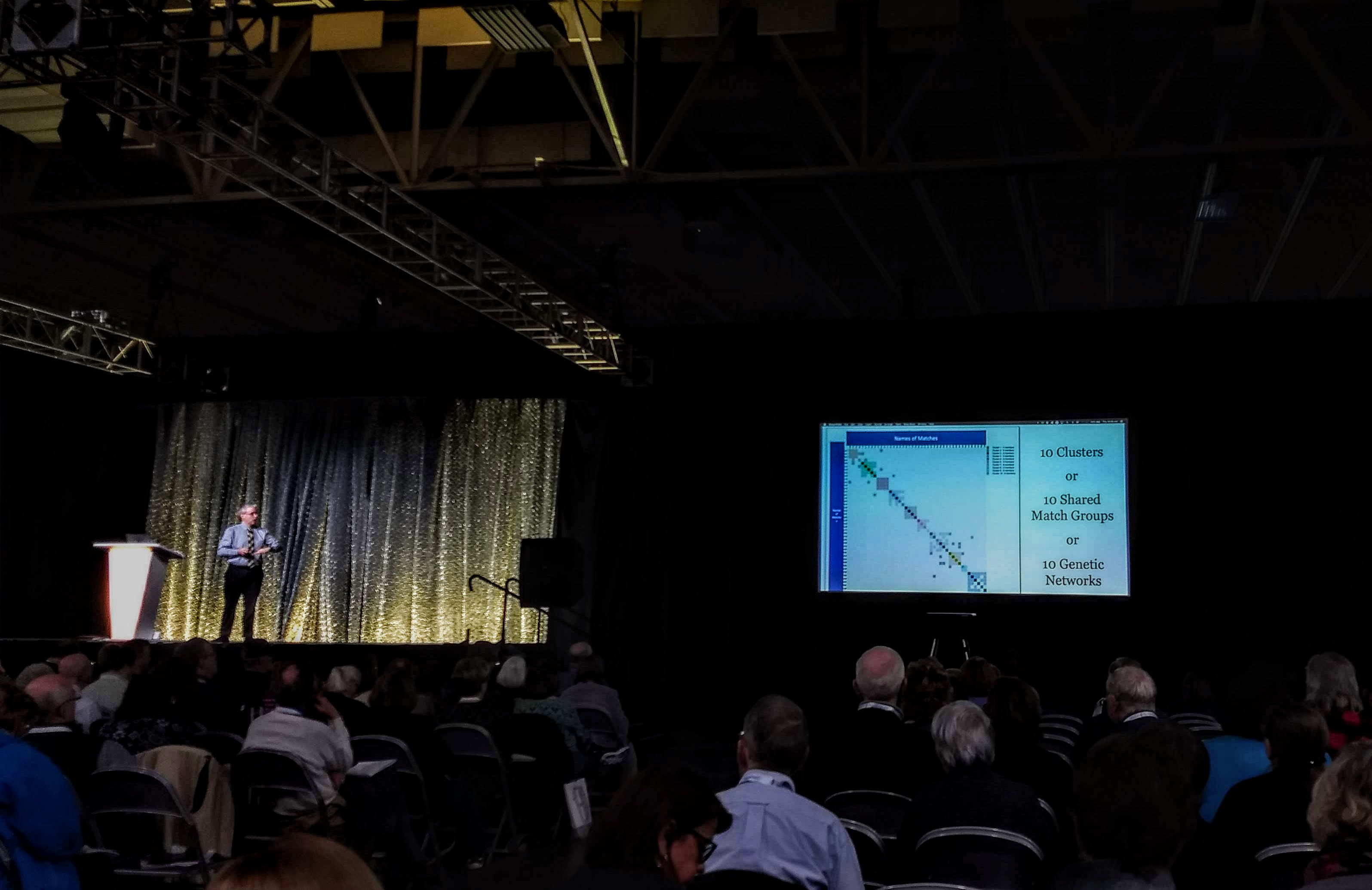
The cluster table is even more useful. It shows if there is a tree connected to a match. It also shows the notes that you have added to a match. These were imported from the testing company. Always write notes for your matches, even if it’s just a hypothesis, so that you don’t have to make that discovery again.

One of the clusters shows lots of notes that Blaine had hypothesized are from the Johnson line in his family.
MyHeritage and Genetic Affiars AutoClustering are now combined in the MyHeritage DNA interface! You can see the AutoClustering tool in your MyHeritage tools. It’s nice to be able to generate this right from MyHeritage.
More Third Party Clustering Tools
NodeXL – If you are new to clustering, this is a challenging process but it is great. You can create ICW clusters of individuals using NodeXL. If you’re using Ancestry data, this is shared matching, not shared segments. You can set up clusters using shared matches and “In common with” lists provided by the companies.
DNA RootSearch – Bonnie Schrack. Creates colorful cluster grouping maps. You can go through each cluster and figure out how they are related. What names in common do all these matches have in common?
RootsFinder – they have a tool to find shared segments and triangulation from GEDmatch and uses the information to create a clustering.
[and more in the syllabus]
How do we use them?
Going back to the example of Sofia Hernandez research group that Blaine created at AncestryDNA, the next step is opening each match’s tree and looking for common ancestors. Then he forms a hyptohesis that everyone in this group is all related through the Alborough family. Then, Blaine would write an email to Sofia, who doesn’t have a tree, and say “it looks like we are related through the Alborough family,” and she is more likely to respond.
Some clusters don’t have any matches with trees, or just have small trees, and that’s difficult. If you really want to use your DNA results, you must build trees for your DNA matches. You want them to do the work for you, if possible, but often you will have to do it yourself. Before you communicate with someone, it’s often easier to bulid a tree. You can write them an email, then wait five minutes to see if they respond (haha) then start building a tree for them. (It’s like waiting in front of the microwave, haha). You can build “research trees” or “quick and dirty trees” very quickly for your matches in Ancestry.
So first, review the trees of your cluster group, then build trees for those who don’t have a tree or who have a small tree. Just because you have a hypothesis that you are related through the Zufelt line, it doesn’t mean that you’re done. You can change the name of the research group so that it’s now called the “Zufelt Research Group” and you can continue to look for evidence to prove the relationships.
“This focused research group might be related to Bart and to each other via a Zufelt family,” with emphasis on the MIGHT.
Sometimes, the cluster appears to be entered around known ancestry.
Often, common ancestry of a cluster is not clear or does not match anything in your current tree. In this case, retian and add to the research group. You may get a new shared match tomorrow that gives you the breakthrough information you needed. Work on building and confirming trees, then wait for better/closer matches.
Blaine goes into his DNA with a specific question. He focuses his research on a particular ancestor who he wants to find more about. Then he focuses on a cluster that he hypothesizes is related through that person.
Don’t over-complicate things. Use the shared matching and shared segment information to point to a group of people to use the trees to identify the common ancestor.









2 Comments
Leave your reply.