With the release of the new DNAGedcom 4, many are wondering the best way to use the tool. David Grawrock, CG, one of our Family Locket Genealogists team members is sharing a helpful tutorial for using this tool. After gathering DNA matches and shared matches into a spreadsheet, you can make network graphs with Gephi and perform other analyses.
-Nicole
Matches
Congratulations, you’ve got your DNA results back and you want to use them in your family research.
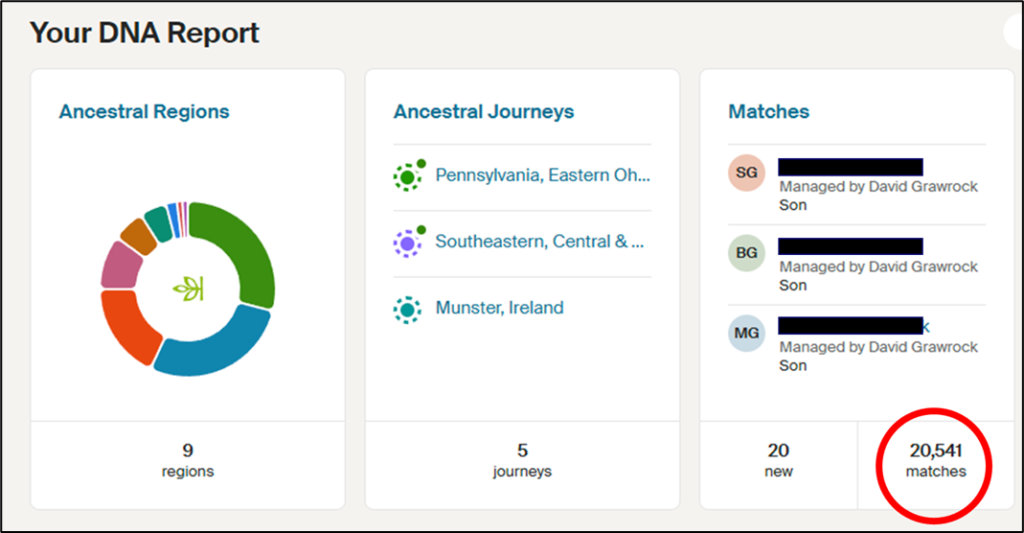
You could type them in one by one, but nobody, well at least sane people, wants to do that over 20 thousand times. And that doesn’t include the shared matches where you from 10 to 100 matches, which ends up looking like hundreds of thousands of entries if not into the millions. Note that my numbers are small as one set of grandparents are Norwegian and the other German, both regions notorious for having few testers. My wife has 46,256 matches for a comparison.
DNAGedCom
After rejecting the idea of manual entry, some sort of automation comes to mind. Thankfully, there is a program that does grab your data, DNAGedCom. The web site is:
Program
DNAGedCom is not free. You must pay for its use. The website has the payment options.
DNAGedCom installs as an application on your local machine after downloading from the website. Installing with the defaults works just fine. Not going to reiterate the installation instructions, if you have problems work with the DNAGedCom team.
Version 4.0
Version 4.0 is currently in beta testing; however, it appears to be stable. As of 10 January 2025, the program can gather matches and ICW from 23, A, and FT. It can only gather matches from MH.
Bleeding Edge
In technical terms using an open beta, such as DNAGedCom 4.0 is not using leading edge technology, but rather bleeding edge technology. The difference is that the bleeding edge is VERY sharp and at times it can cut you, or in other words you are now bleeding. To avoid cutting yourself, backup often, keep a series of backups, and be ready for a potential hiccup. For “standard” use of getting matches and the ICW gathered, I personally haven’t had an issue with the program since way back in the closed Beta phase. The code works like it should. There are still some quirks, but the team continues to weed out those quirks.
Database Considerations
Database
The program, when gathering, stores the information in a SQL database in a location selected by the user, suggestions as to where to store are next. The database is a standard SQL database and capable of being read by SQL readers such as DBBrowser or code written in Python.
To select the location, first use the “Change Settings” button.
Note that when you restart the program, the database in use when you previously quit is automatically loaded as the database in use.
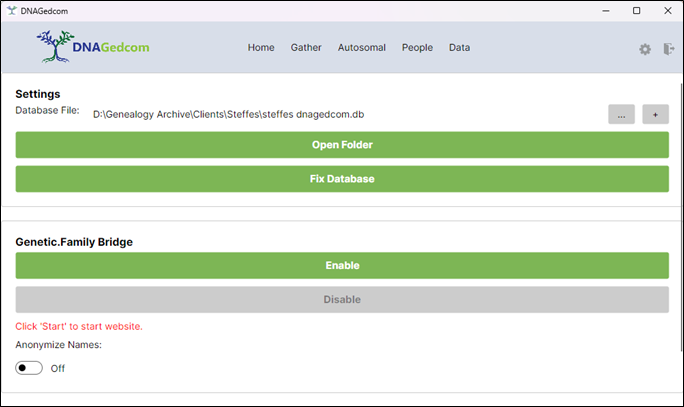
Switching databases
If the selected database is not correct, and there is a pre-existing database, then click on the three-dot button “…” and navigate in the file structure to the desired file.
If you want to create a new database, then click on the plus button “+” and navigate to the folder and name the database.
Database naming
The files use the standard .DB extension to indicate the file is a database. I like to name my databases with the program using the database, so as you can see the database name includes dnagedcom. That is merely a convention that I use. There is no requirement to use the program name in the file name.
Database file location
Where you store the file depends on how many research projects you have, how many companies you need to download from, and how time sensitive your needs are.
Single Tester, Single Company
When dealing with a single tester from a single company, the location can be anywhere. Personally, I like to have the file in a folder with my project, but it doesn’t really matter.
Single Tester, Multiple Companies
If you use a single database for all gathers, then the project folder works well.
If you use a database per testing company, the files MUST all be in the same location. The reason is fully explained in the Multiple Gathering section.
Multiple Testers, Single Company
You SHOULD use a single database in this situation. The reason is that it will drastically reduce your gather time and size of the database. The reason is that the ICW information is in many instances, duplicated. For example, you are A, first cousin B is the other tester, and C & D are second cousin matches. The first gather, for A, gets the AB, AC, AD, BC, BD, and CD. On the second gather for B, DNAGedCom can skip the matches already gathered, which are the AB, AC, AD, BC, BD, and CD.
Multiple Testers, Multiple Companies
I recommend the single database for the same reasons as the multiple testers, single company recommendation.
If you do separate into multiple files, you should separate them by company to gain the advantage of the gather time speed up.
Multiple Gathering
If you have multiple testers or companies, there is the obvious question of, “Can I do more at the same time?”
Maybe. That’s a horrible answer, but the truth as of January 2025, and the 4.0 beta test version, there are some issues.
Given that I’ve had to do multiple gathers, across multiple testers, and across multiple companies, I’ve felt the pain, or had to rerun entire gathers, from these options.
Gather two testers from the same company
Two testers from the same company, why not run two instances of DNAGedCom to gather faster?
DO NOT DO THIS. The reason is not technical but practical. While it might work, the gathering process takes up resources of the testing company. Doing this for multiple testers, from your single account, can put a dent in throughput for others on the website.
Gather same instance, different companies, same database
In this model you run a single copy of DNAGedCom and start gathers at more than one company, all to the same database. The design of DNAGedCom SHOULD allow this. It’s not deeply tested and may have hiccups. The hiccups are difficult to discover.
Given the difficulty of discovering the hiccups, I do not recommend this type of gather until the DNAGedCom team explicitly state this is tested and working.
Gather different instances, different companies, same database
In this model you start DNAGedCom twice, or more, with all instances pointing at the same database, and start gathering for different companies. This SHOULD work but has the same caveats as using the same instance.
Given the difficulty of discovering the hiccups, I do not recommend this type of gather until the DNAGedCom team explicitly state this is tested and working.
Gather different instances, different companies, different databases in same folder,
In this model you start DNAGedCom twice, or more, each instance pointing to a different database, the databases are all in the same folder and start gathering for the different companies.
While this worked in 3.0, this does NOT work. The team want this to be right in the future, but as of January 2025, do not attempt this.
Gather different instances, different companies, different databases in different folders,
In this model you start DNAGedCom twice, or more, each instance pointing to a different database, the databases are in different folders and start gathering for the different companies.
This did NOT work in 3.0 and it is NOT working in 4.0. It WILL corrupt the databases. The only recovery mechanism is to go to a backup or do the gathers from scratch.
Conclusion
Currently, the only concurrent processing I think is worth trying is same instance, same database, different companies.
Gathering Quirks
Time
How long will the gathering take? There is no hard and fast number, it all depends on how many matches to gather, how many of those matches have oodles of shared matches, and the load on the testing web site.
For instance, with my twenty thousand matches, a first-time download into a new database takes days. For my mother-in-law, with her Ashkenazi heritage, it’s weeks. This is especially true if you gather to the minimum size like 8 cM.
To minimize the time, my technique is to filter the first gather to 20 cM and above. The resulting database, while not complete, provides a starting point for analysis. After doing that gather, I’ll filter from 15-20 cM, and then a gather at 10-15. Only after those are done will I do the final gather of 8-10 cM. With those gathers complete, once every month or so, I’ll do a gather on the current database to catch any new matches.
Count
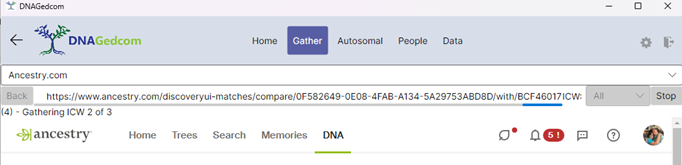
As you gather, on the left side of the screen, there is a count. That count is how many ICW matches need to be gathered for the current match. It’s helpful but it doesn’t tell you how many matches are remaining to gather.
Pausing
After gathering for some time, the gather can pause on an individual match. If you see the same name for some period, dependent on your patience, you can unfreeze the gather by pushing the stop button on the right. The great design point of DNAGedCom is that an interruption doesn’t really affect the gather and when restarted DNAGedCom picks up where it left off. This includes things like being interrupted by an OS reboot. If a reboot occurs in the middle of your gather, just relaunch DNAGedCom, filter for the same cM size, and restart the gather. DNAGedCom will figure out where it was and continue. This feature is critical to understand that you won’t lose the 2 weeks long gather that was ongoing.
Conclusion
This is only the start of what you can do with DNAGedCom, there are reports it can directly create. In addition to those reports, using the database for external activities, like network graphs in Gephi are possible.
If you are attempting to do more with your DNA results, then what is provided by your testing company, I strong encourage you to obtain and use DNAGedCom.
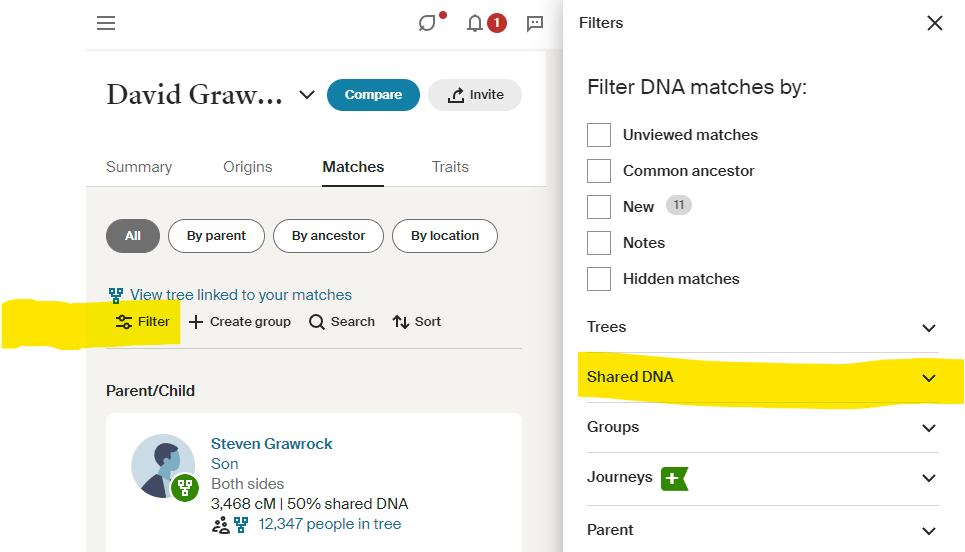
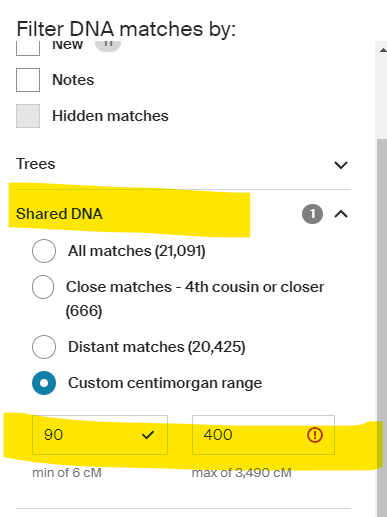
Additional Filter Images
Updated 5/5/2025








10 Comments
Leave your reply.