
Imagine starting on a brand-new research project with DNA matches and an unfamiliar family tree. You want to get the most out of your precious research time and efficiently organize the DNA matches so you can focus on the family line(s) of interest.
– What do you do first?
– What’s the most effective method?
Great questions! Try the methods outlined below to get started efficiently and effectively.
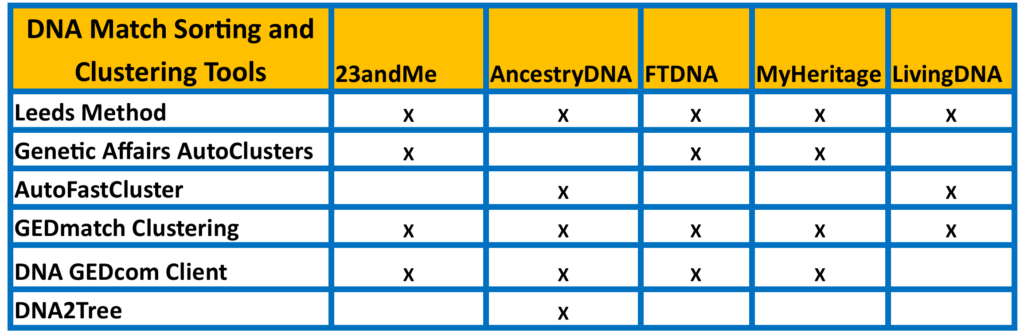
Make a Leeds Method chart
Spend 10-20 minutes creating a Leeds Method DNA Color Cluster chart. This will help you become familiar with the groups and identify the family lines to focus on. This chart can be a foundation to build on with automated cluster programs.
Open an excel spreadsheet, enter the DNA match names for 2nd -3rd cousin matches, and color code them. DNA matches can be found in the following ways:
– Use the shared matches feature at Ancestry
– ICW feature at Family Tree DNA
– “Find Relatives in Common” feature at 23andMe.com
– “Shared DNA Matches” in MyHeritage,
– “Relatives [DNA tester] and [DNA Match] have in common” in LivingDNA
Dana Leeds has written excellent clear instructions on this method here: https://www.danaleeds.com/dna-color-clustering-the-leeds-method-for-easily-visualizing-matches/
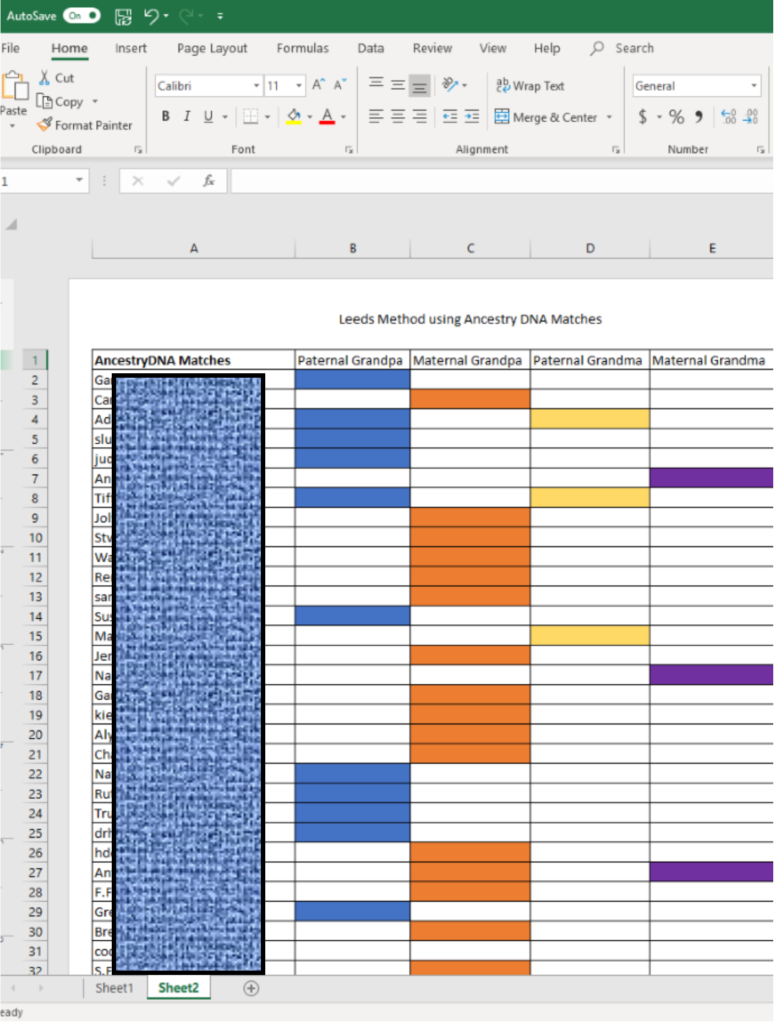
Leeds method chart
Generate AutoCluster Reports – Genetic Affairs
Another fast way of separating 23andMe and Family Tree DNA (FTDNA) matches is the AutoCluster program from GeneticAffairs.com. Evert-Jan Blom developed an automated method of clustering DNA matches. He worked in collaboration with MyHeritage and GEDmatch to develop the tools in their websites as well. I like the Genetic Affairs AutoCluster reports for a variety of reasons.
1. The report generates quickly and shows multiple colored clusters of DNA matches separated into groups. The groups illustrate people that share DNA with the test taker and with other DNA matches. Not everyone in the bright colored cluster is related to each other directly, but they do group around one shared ancestral line.
2. At the bottom of the page under the cluster report, there is an interactive, searchable list of the DNA matches included in the analysis. The list includes the DNA matches names, the amount of DNA shared in cM, number of DNA segments, ICW (In Common With) the number of DNA matches in the cluster that have DNA in common with each other. The assigned cluster number, and the number of people in their family tree. This number is hyperlinked so that you can click on the number and go straight to the DNA match’s tree. The notes you have entered in the DNA website also show on the interactive list. I found the notes feature especially helpful since it helped me quickly identify and remember the DNA matches.
3. As you hover over the colored clusters or the Clusters key, a list will show the DNA matches names.
Read more here: https://geneticaffairs.com/features-autocluster.html
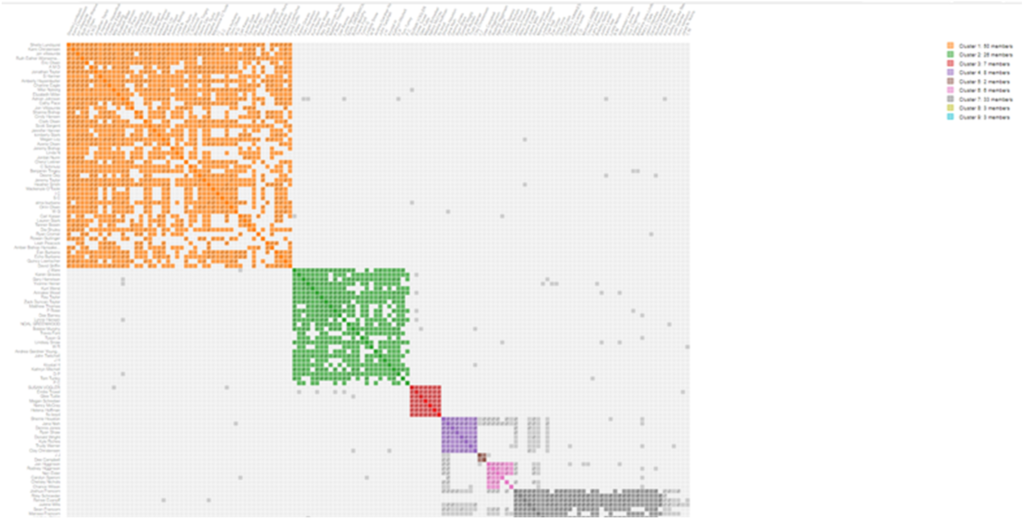
23andMe AutoCluster Report
AutoCluster Reports from MyHeritage
AutoCluster reports are generated by taking the following steps on the MyHeritage website. Choose DNA < DNA Tools < AutoClusters < Explore. An AutoCluster report will be generated and emailed to you. Read more here: https://blog.myheritage.com/2019/02/introducing-autoclusters-for-dna-matches/
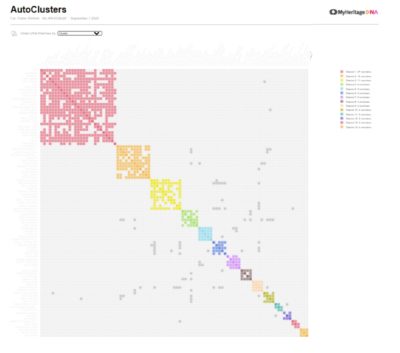
MyHeritage AutoCluster report
GEDmatch Automated Clusters
Use the Tier 1 feature called “Clusters, Single Kit input, Basic Version” to generate clusters of DNA matches grouped along family lines. Enter the GEDmatch kit number of the person you are working with. You can use the default settings or change them to a higher threshold. In the example below, I used a threshold of 50 cM at the lower end and 400cM at the upper end. There were not a lot of matches shared with this DNA tester in the GEDmatch database, so the cluster chart is small but still helpful.
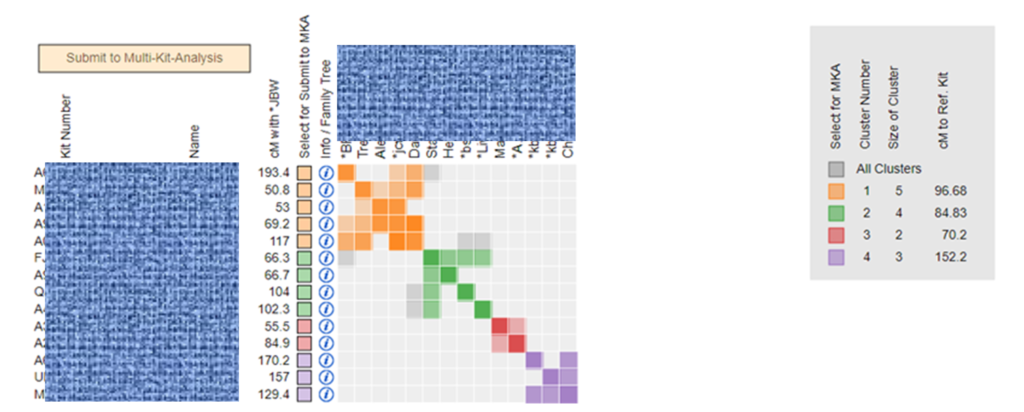
GEDmatch Cluster image
![]() Hot tip: Genetic Affairs also has AutoTree and AutoPedigree features that can help build a family tree using information from shared DNA matches’ family trees.
Hot tip: Genetic Affairs also has AutoTree and AutoPedigree features that can help build a family tree using information from shared DNA matches’ family trees.
DNA 2Tree App for iOS
This is a newer program that is a subscription app for iPads or iPhones. I’m excited about this iOS program that has helpful tools to separate matches AND identify common ancestors. The common ancestors are found by comparing family tree information from the family trees connected to your DNA matches profiles. What is even better is that it works with AncestryDNA matches!!
You can choose to load every DNA match in a profile or just some of them, which helps focus in on either a paternal or maternal side of a tester’s family. See the image below for DNA match loading options.

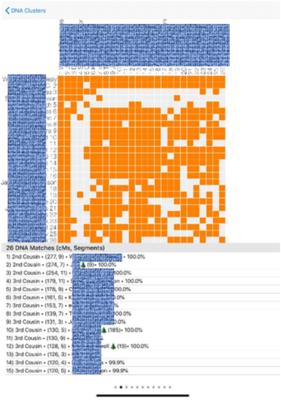
DNA match loading options and Single DNA cluster indicating the DNA matches, shared DNA in CM, and family tree
I especially like the app’s ability to zoom in on a colored cluster and see the list of people in a cluster and even access a list of the genealogical pathway from the DNA match to a common ancestor.
Some clusters don’t list a common ancestor or common surnames which happens in the case of DNA matches with no tree attached to their account. The program can still identify DNA matches that share DNA with you and with each other, even if there is no family tree data available.
The Collins Leeds Tool – DNA Gedcom Client
Use the Collins Leeds tool to create colored cluster charts with DNA match data from Ancestry, 23andMe, FTDNA, MyHeritage, and Gedmatch. To access the data, gather it from the DNA testing companies via the DNA Gedcom Client tool. Gather the matches overnight or for a few days before you begin your project. It takes a while to load all of the data, but it is worth the time because of the other programs such as GWorks, JWorks, and KWorks that also use the data. You can still work on your computer while it gathers matches in the background. Learn more about the Collins Leeds Method here: https://genetic.family/Help/CLM.
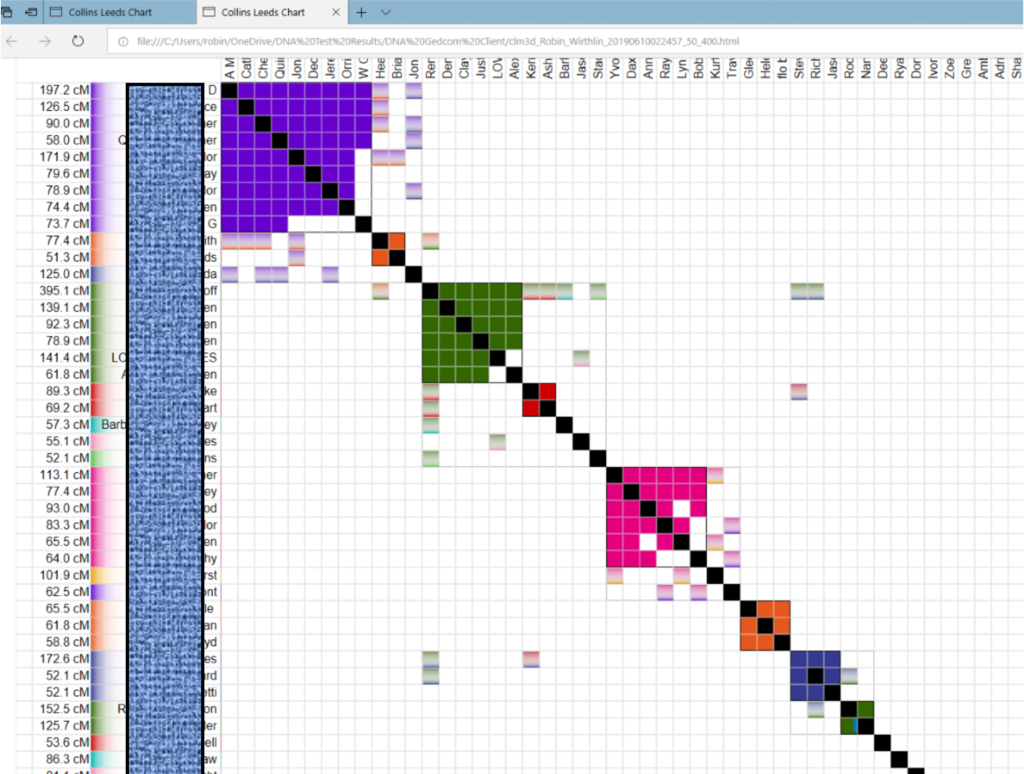
Collins Leeds chart
Manual Input Programs
If downloading the DNA match information is not possible via an online 3rd party tool, there are some programs that will help you analyze the data fairly quickly. These involve manually entering DNA match data. In May of this year, AncestryDNA restricted third-party analysis tools from using its database. These important workaround programs were developed and allow an alternative method of gathering DNA match data for analysis.
AutoFastCluster for LivingDNA and Ancestry
This program is called AutoFastCluster because it can return the results of manually entered DNA data in a few seconds, rather than hours or the next day that it typically takes to generate Genetic Affairs AutoClusters. To use the program, manually enter the DNA match names, the amount of shared DNA in centiMorgans (cM), and any notes.
You can choose the maximum and minimum amount of shared DNA you want to be analyzed. You can export the matches and shared matches in a .csv file or Excel file for use in other DNA analysis programs such as DNA Painter. Learn more here: https://geneticaffairs.com/features-autofastcluster.html
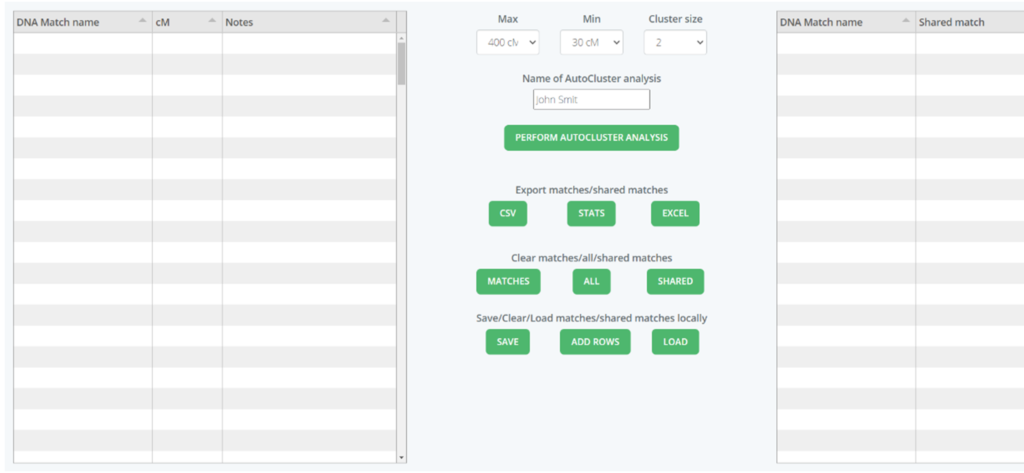 AutoFastCluster data entry table
AutoFastCluster data entry table
Shared Clustering by Jonathan Brecher
Shared Clustering is another useful Open Source program for clustering your DNA matches at the beginning of a research project. Jonathan Brecher created an Excel template that holds DNA information use to cluster DNA matches. It doesn’t matter which DNA company the data comes from, but you need to enter the information by hand. You can extract the names and amount of shared DNA from a downloaded .csv file generated by a DNA testing company and paste that information in the template that Jonathan Brecher has created. You can read more about this method here: https://github.com/jonathanbrecher/sharedclustering/wiki? and here: https://github.com/jonathanbrecher/sharedclustering/wiki/May-2020-status-update
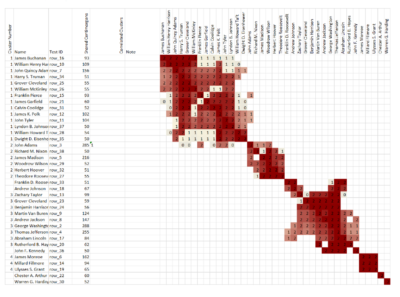
Shared Clustering image used with permission from Jonathan Brecher
Try using one or more of these methods the next time you start a new genetic genealogy project. Making sense of the data will make your research will not only go faster, but you’ll also be researching like a pro with DNA! To try a new method of clustering your matches, try a network graph. Learn more about using Gephi to make network graphs with Nicole’s series here: https://familylocket.com/tag/gephi/.









6 Comments
Leave your reply.