
If you could name one goal for your family history research, what would it be? Would DNA help you achieve your goal? If so, there is an essential tool that will help you progress toward it.
In your DNA match list, you’ll see an estimated relationship and the amount of DNA you share with each relative. If you build a family tree based on just the predicted relationships, it will be difficult, and possibly incorrect. You need a tool to help you discern not only possible relationships, but also the probable likelihood of specific relationships you share with your DNA matches.
How will discerning the probable relationships between you and a DNA match help you? A relationship tells you where to place the DNA match in your family tree. A relationship directs you to a shared ancestor. Sometimes the shared ancestor is the ancestor you are seeking to achieve your goal!
The tool you need is the Shared cM Project tool.
The estimated relationships in a DNA match list may not indicate the actual relationships between you and your DNA matches. This is because there is a wide range in the amount of inherited DNA that may be shared between two people in a specific relationship. The variance in the amount of shared DNA is due to the random nature of DNA recombination and inheritance.
While each parent passes 50% of their DNA to their children, that 50% is a mixture of an average of 25% of each of the grandparent’s DNA. One grandparent could contribute 22% and the other grandparent 28%, which averages 50%. Going farther up the family tree to great-grandparents, their DNA goes through 3 meiosis or recombination events to reach you. An average of 12.5% of your great-grandparents’ DNA is passed on to you which could be made of 6% from one and 18.5% from the other, or any combination that creates an average of 12.5%. The random mixture of the average percentage helps explain why some ancestors’ DNA may not be detected in each of their descendants.
Before the Shared cM Project was published, scientists calculated the expected amount of shared DNA between people in specific family relationships.[1] The table below lists DNA and relationship data and was adapted from the “Autosomal DNA Statistics” Wiki page for the International Society of Genetic Genealogy (ISOGG). The challenge of using calculated expectations in genealogy research is that in real life, there is more variation in the amount of actual shared DNA in certain relationships.
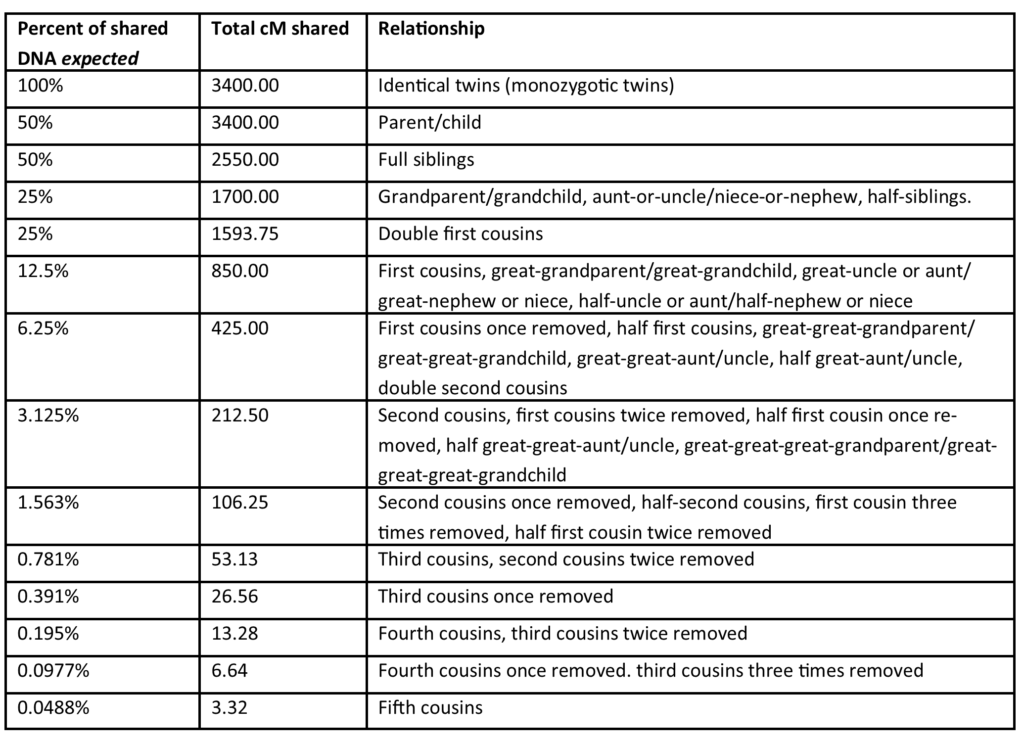
Autosomal DNA expected inheritance
The Shared cM Project Tool (https://dnapainter.com/tools/sharedcmv4)
Blaine Bettinger, Ph.D. sought and still seeks to collect data consisting of amounts of shared DNA observed in known family relationships. He created the Shared cM Project and invited people to submit data. Version 4.0 of the Shared cM Project was based on nearly 60,000 DNA tester’s submissions of the amount of DNA they shared with DNA matches in known family relationships. The data analysis showed that the amount of shared DNA fell into a range for each relationship. The number of data points for amounts of shared DNA naturally fell into bell curve shaped groupings for each meiosis (reproduction/recombination event).
The Shared cM Project tool can help you estimate relationship possibilities for your DNA matches. The tool is an interactive chart that shows the centimorgan (cM) ranges for various family relationships. Jonny Perl created DNA Painter and the interactive version tool that automates and streamlines the process of estimating relationships between you and your DNA matches. The probabilities are based on stats from Leah Larkin, Ph.D., (The DNA Geek).

To use the shared cM chart:
1. Enter the amount of DNA you share with a match. To find the amount of cM of DNA that you share with a DNA match, look in the DNA match list on a DNA company website.
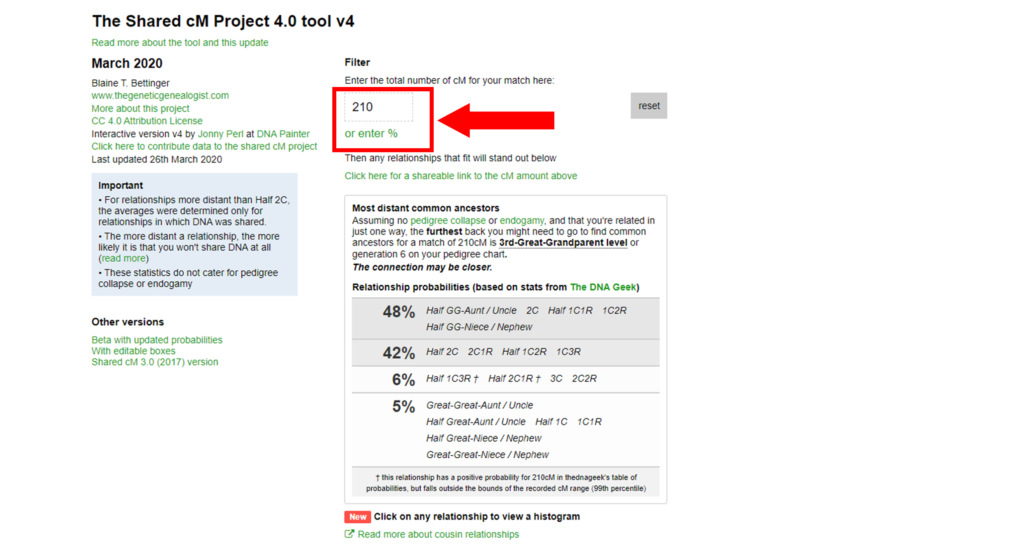
2. A list of all relationship probabilities will open. You may share any one of the relationships in the listing with your DNA match. The highest probabilities are shown at the top of the list. Scroll down to see the possible relationships highlighted in the Shared cM Project chart.

3. Determine which relationships have the closest average amount of cM of DNA compared to your actual cM of shared DNA.
4. Look at the histograms (found by clicking on the relationship boxes in the interactive Shared cM Project tool) and compare the DNA match’s cM amount to the histogram’s highest peak for the relationships determined in step 3. The most likely relationships are closest to the highest peak, which generally corresponds with the average cM listed for a relationship.
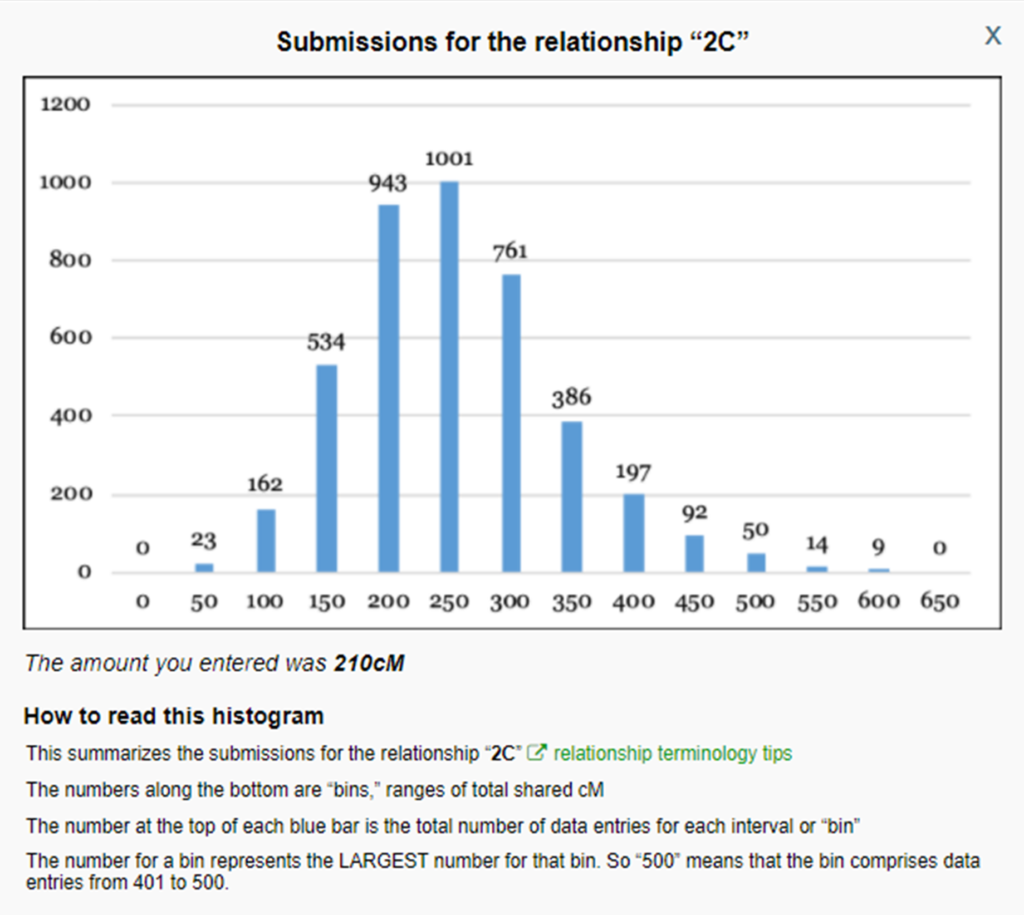
Another feature is the Shared cM Project 4.0 tool v4 beta. To open the beta version, click on the “beta with updated probabilities” link on the left side of the page under “Other versions” heading. The probabilities of relationships were updated and expanded. You can learn more about it in Leah Larkin’s 25 May 2020 blog The DNA Geek “Improving the Odds.”
Some other features of the Shared cM Project tool are the ability to edit the boxes in the chart. Click on “with editable boxes” on the left side under the heading, “Other versions” to open a new screen where you can type in the names of the people you are researching. This will create a custom chart that will allow you to add the names of the DNA matches you are focusing on in a specific research project.
To review:
– Enter the amount of DNA you share with a match. Look in the DNA match list on a DNA company website to find the amount of cM of shared DNA that you share with a DNA match.
– A list of all relationship probabilities will open. You may share any one of the relationships in the listing. The highest probabilities are shown at the top of the list. Scroll down to see the possible relationships highlighted in the Shared cM Project chart.
– Determine which relationships have the closest average amount of cM of DNA compared to your actual cM of shared DNA.
– Look at the histograms (found by clicking on the relationship boxes in the interactive Shared cM Project tool) and compare the DNA match’s cM amount to the histogram’s highest peak for the relationships determined in step 3. The most likely relationships are closest to the highest peak, which generally corresponds with the average cM listed for a relationship.
This is an estimate of the relationship. The actual connection may be different, but this method will help you narrow down many possible relationships. Your next steps involve using documentary evidence such as birth, marriage, and death records, church, census, military, and other records to confirm relationships, and build connections between family members. It is important to rule out relationship options before you really know how a match is related to you. It may may require a combination of other DNA tools and methodology to have certainty of the relationship.
Follow the steps and use the information to make progress toward your family history goal. As you incorporate DNA in your genealogy research, you will be able to confirm genetic connections to your known relatives and hopefully identify new ancestors!
Check out our new book Research Like a Pro with DNA in print or Kindle editions on Amazon!
To learn more about using DNA in your family history research, try the Research Like a Pro with DNA eCourse or a live instruction Research Like a Pro with DNA study group in February 2023.
[1] International Society of Genetic Genealogy, “Autosomal DNA Statistics,” rev. 8 November 2020, ISOGG Wiki (https://isogg.org/wiki/Autosomal_DNA_statistics).
Updated 12 May 2022









Leave a Reply
Thanks for the note!