Do you feel overwhelmed by your long list of genetic matches? How do you know how you’re related to them? In this post, I will explain the steps you should take after you receive the test results for the person that you decided to test, whether it is yourself or a family member, and how you can discover the relationships.
In my last post, I explained the first steps that you should take for a DNA research project. As a review, you should first make a research objective, decide which type of DNA test to use, and decide who the best person is to take the test. After you finish those steps and receive the results, then you’re ready to start researching and analyzing.
Most people take a DNA test to see their ethnicity estimates. While those can be fun and may even be helpful for certain DNA projects, we will be primarily interested in the “shared matches” – your genetic cousins! All the major testing companies have this type of feature, but the actual name varies on the company. Depending on how many of your biological relatives that you know and have taken DNA tests, you may already be able to identify some of the people on your DNA match list.
The screenshot below shows my matches from the Ancestry DNA website. The default order is closest genetic relation to furthest genetic relation, so you are more likely to recognize the names at the top than at the bottom.
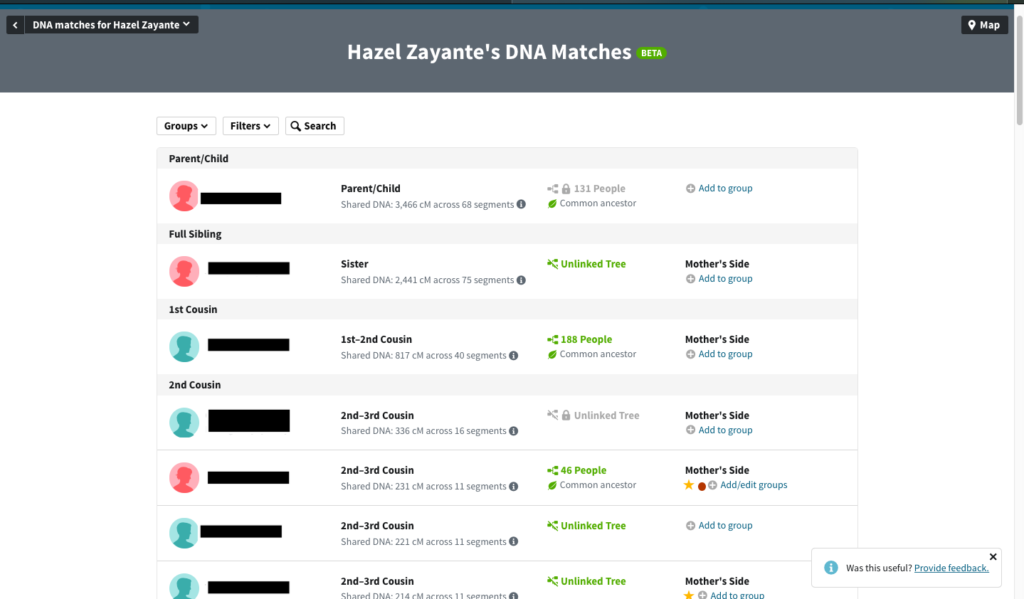
You will notice the estimated relationship of the match and the number of centiMorgans (cM) next to the name of the match. Put simply, cMs are a unit of shared DNA, so if there are a high number of shared cMs there is likely a close genetic relationship. Since DNA inheritance is completely random, there is no formula to definitively conclude the relationship for most individuals using DNA results alone.
In order to help researchers discover the relationship between themselves and their genetic matches, Blaine Bettinger developed The Shared cM Project Tool. It is simple to use: enter the number of shared cMs between you and your genetic match, and the tool will highlight which relationships are possible and show percentages for which relationships are the most likely. Make sure that you are using version 4 as it includes the relationship probabilities. Here’s an example of using the tool with my results:
Notice the fourth genetic match on my list, 336cM (see image above). The estimated relationship according to Ancestry is 2nd-3rd cousin, but we can get a more complete estimate from The Shared cM Project.
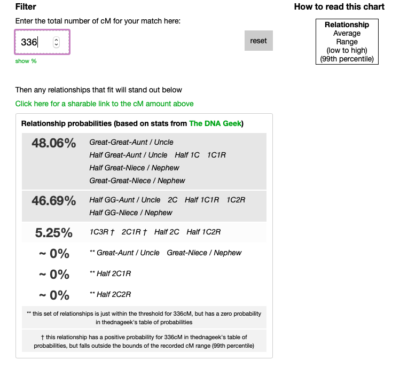
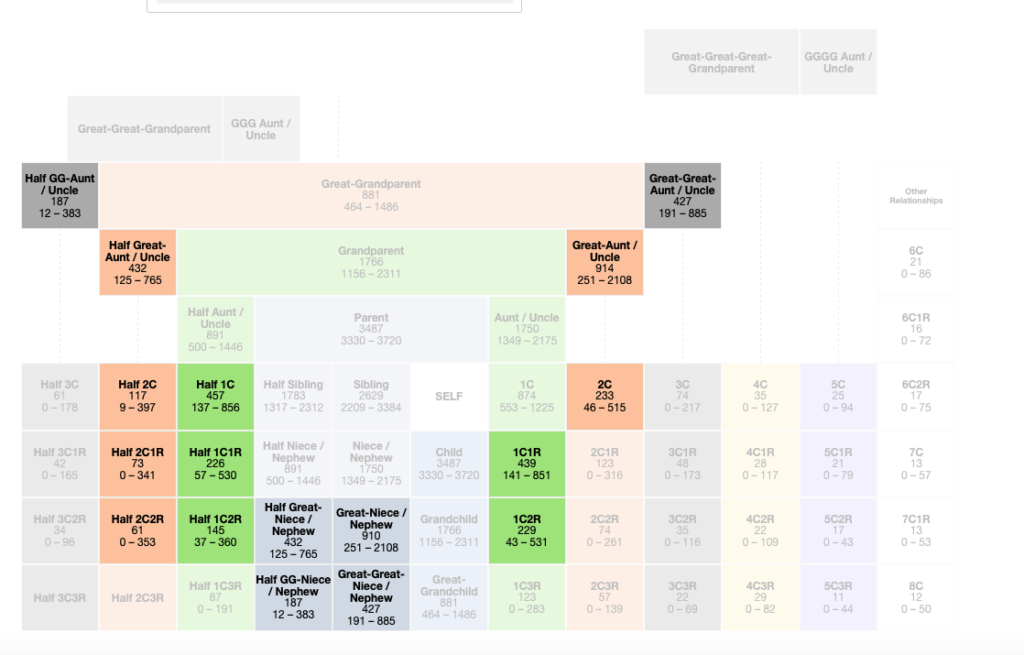
There are a lot more relationship possibilities here than just 2nd or 3rd cousins! It seems a little overwhelming, but in the long run it is helpful to know all of the possibilities so that you can discover the accurate relationship. This match happens to be my second cousin, so we see that the tool is accurate in identifying possible relationships. Remember that just like the relationship estimates from Ancestry or other testing companies, these are also estimates. However, it is still very helpful in hypothesizing the relationships of your genetic matches. For adoption cases, this is key and will help you break through your brick walls. I will show you more of that in a later post.
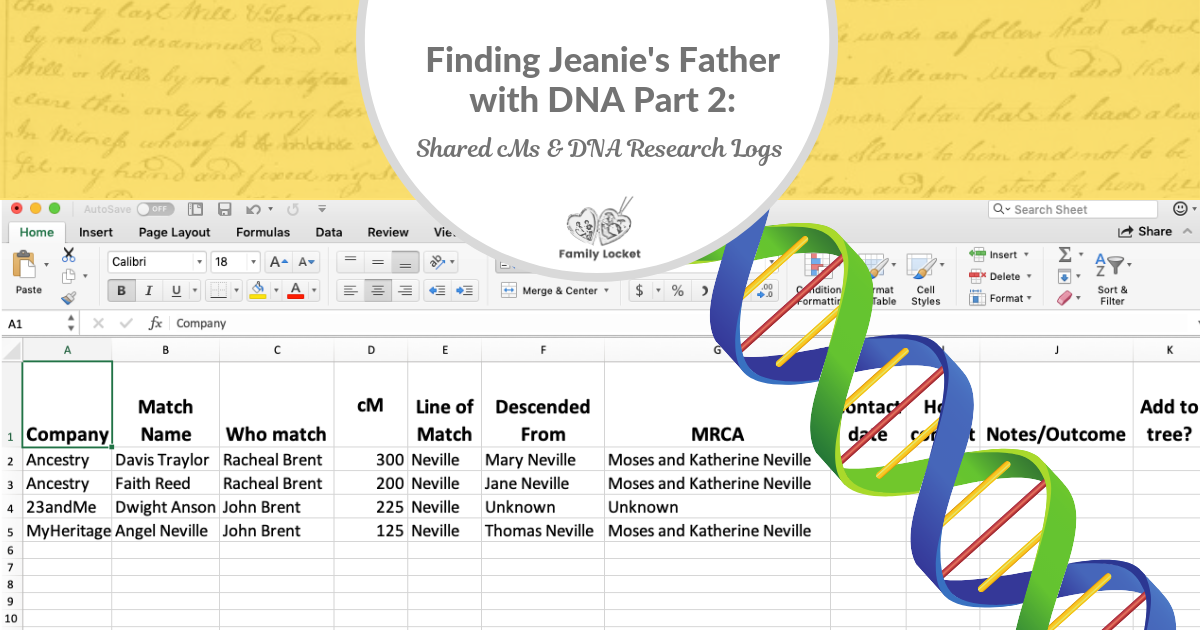
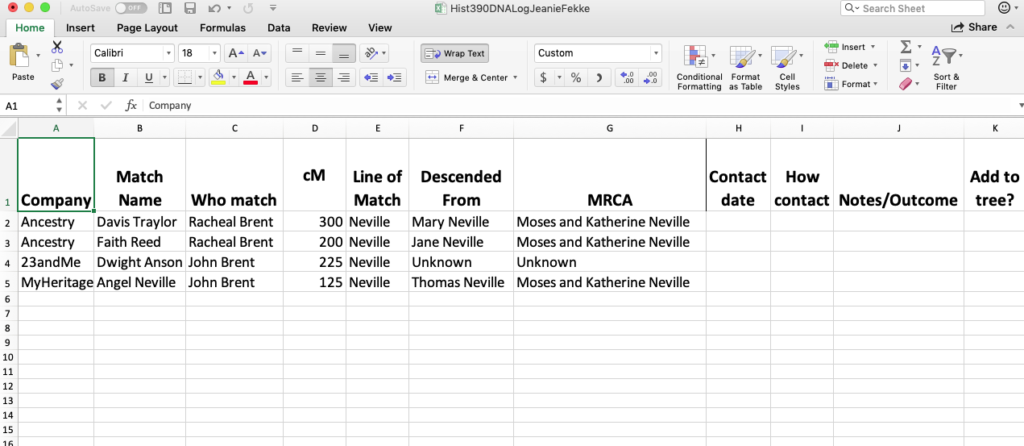
After you receive your results, it’s a good idea to familiarize yourself with the names you see on your shared match list. An essential part of the Research Like a Pro process is to keep a research log, and this includes DNA projects. Do you see any surnames that you recognize? Are there any close matches whose names you don’t recognize? Have they uploaded trees? All of this information should be recorded in a research log. If you contact any of your genetic matches, that should be recorded, too. The sample research log below was created by a family history professor at Brigham Young University, Karen Auman. Feel free to use whatever format or application works for you.
Are you ready to start organizing your DNA matches and get to know your genetic cousins? DNA research has helped me break through multiple brick walls in my family tree, and I know that with some work it will help you too!
To read the other posts in the series, click below:
Part 2: Shared centiMorgans and DNA Research Logs
Part 3: Identifying a Familial Cluster
Part 4: Combining Traditional Research with DNA Analysis
Part 5: Using Multiple Databases









Leave a Reply
Thanks for the note!