Handwritten text recognition by large language models (LLMs) has become much better with the latest releases of ChatGPT 4o and Claude 3. 5 Sonnet. Claude 3.5 Sonnet is the smartest LLM available today. See Anita Kirkovska, “Claude 3.5 Sonnet vs GPT-4o,” vellum (https://www.vellum.ai/blog/claude-3-5-sonnet-vs-gpt4o). I decided to test Claude 3.5 Sonnet with one of my favorite tasks – handwritten text recognition, a challenging task for LLMs.
To test the capabilities of Claude 3.5 Sonnet, I created a manual transcription of the first part of this 1829 North Carolina deed:

Lincoln County, North Carolina, Deeds 34:546, Joseph C. Pearson to Archibald Dyer, 14 January 1829; image, FamilySearch (https://www.familysearch.org/ark:/61903/3:1:3QS7-L969-TXKS : accessed 28 June 2024).
Then I provided the image to Claude 3.5 Sonnet with the following prompt:
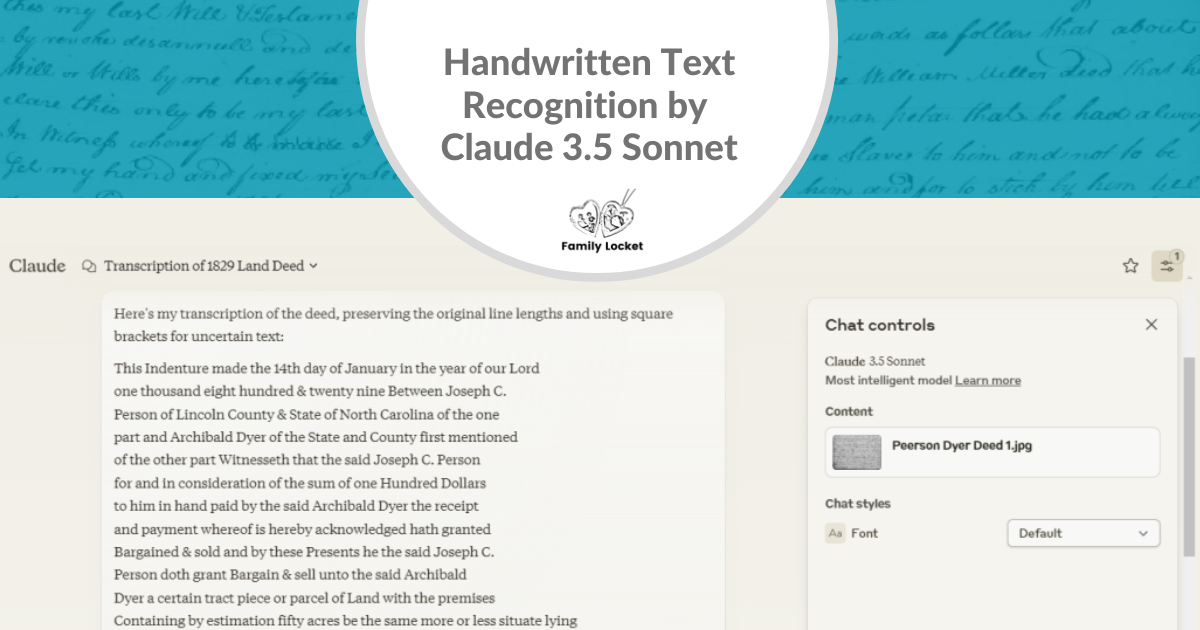
![]()
The purpose of asking the model to preserve the lines in the document is to make checking the transcription easier. The result was stunningly accurate. The main mistake Claude made was changing the grantor’s surname from Peerson to Person.
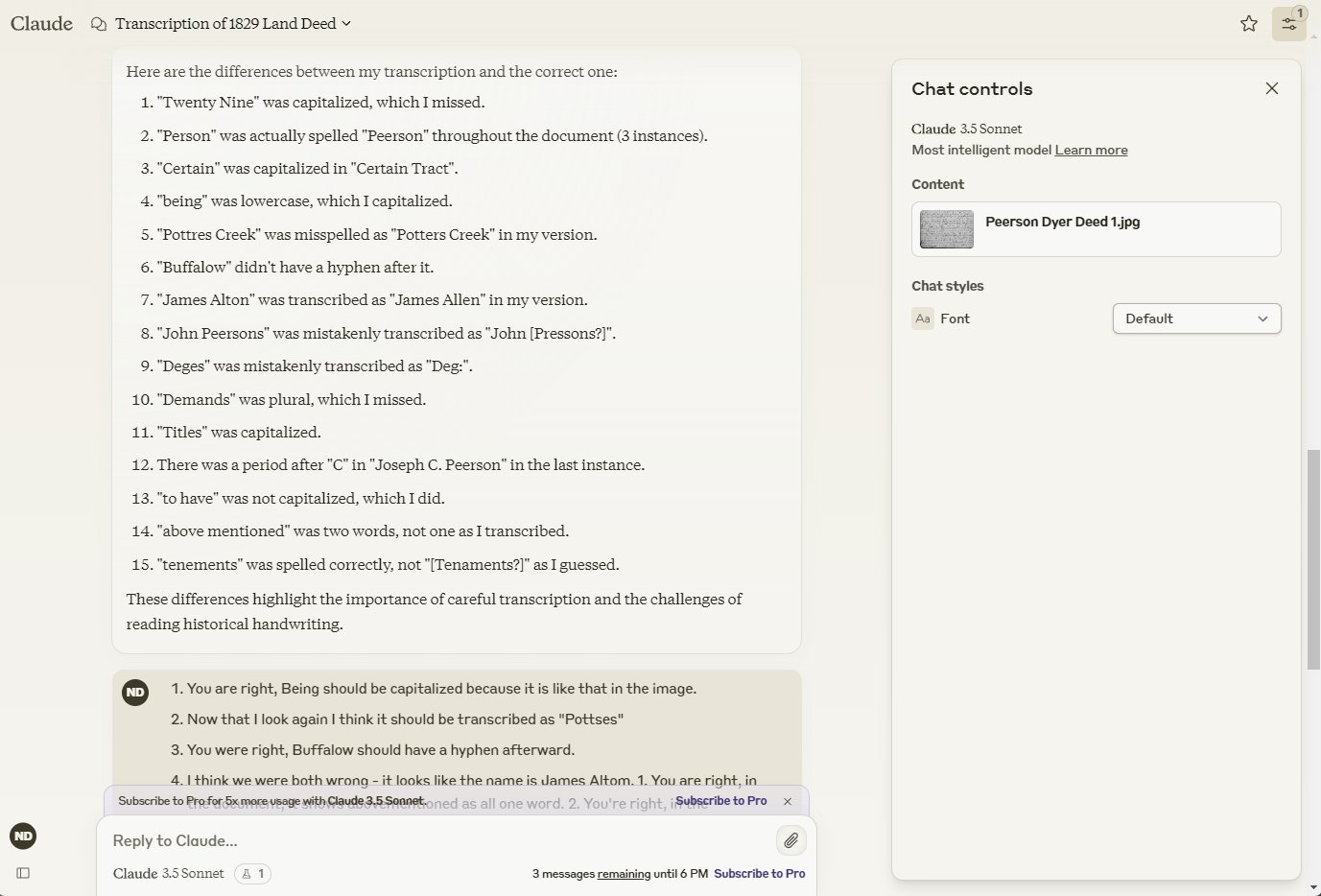
![]()
I then provided my manual transcription, and prompted Claude, “Here is the correct transcription. List all the differences.” The response was a list of fifteen differences. To my surprise, in four cases, Claude’s transcription was right and mine was wrong. I missed capitalizing a word, omitted a hyphen, failed to combine two words, and spelled a word correctly when it was spelled incorrectly in the document (possibly due to Google Docs autocorrection).
In two other cases, we were both wrong, and closer examination of the original document showed the name of the creek to be Pottses Creek (not Pottres or Potters) and the surname of a a neighbor to be Altom (not Alton or Allen).
The other nine differences were slight mistakes in capitalization, spelling Peerson as [Pressons?], inaccurately transcribing superscripted letters as Deg:” instead of Deges (where the final es is superscripted), a missing “s” at the end of a word, and a missing period after the C in Joseph C. Peerson.
I recognized later that we both missed superscripting “th” after the 14.
As I have compared Claude and ChatGPT performing handwritten text recognition, I’ve found Claude to produce transcriptions with higher fidelity to the original, without changing misspellings, expanding abbreviations, and altering unusual capitalizations.
I’m blown away by the ability of Claude 3.5 Sonnet to accurately transcribe this deed with only one major mistake!
Tips
Here are some tips I’ve learned for transcribing handwritten text with ChatGPT and Claude.
- Choose images to be transcribed that are in prose or narrative format rather than tabulated data like taxes or censuses, which are much harder for the LLM to read.
- Use image files (.jpg and .png) instead of PDFs. PDFs are much more difficult for the LLMs to transcribe.
- Crop deed images from FamilySearch so you only see one page instead of two pages of an open book.
- In the prompt, ask to preserve the original line lengths for easy comparison with the original.
- Ask for illegible words to be placed in square editorial brackets so you can quickly review any words it had trouble recognizing.
- Ask for the transcription to have high fidelity to the original without changing abbreviations, and placing superscripted letters in square brackets with a caret symbol, i.e. 14[^th]
- If you already know the names of the people, providing them in the prompt help you get a more accurate transcription the first time through. The models struggle to read proper nouns and dates.
Now it’s your turn. Find a letter, deed, will, or some other document that you’ve already transcribed. Put the image file into Claude 3.5 Sonnet (you don’t need a subscription, just a free account), and see how it does. Compare it to your transcription. Share with us in the comments.
Learn More
Learn more about Using AI Tools in our 4-day workshop, Research Like a Pro with AI, July 29-August 1, 2024.








10 Comments
Leave your reply.