![]()
Would you like to automate the transcription of handwritten documents? Or quickly search for a particular name in a large probate or pension application file? Transkribus is an innovative platform that harnesses the power of artificial intelligence (AI) to make deciphering old handwriting faster. Whether you’re tracing your family tree or researching historical figures, Transkribus can save you countless hours by automatically transcribing handwritten documents into searchable text. In this blog post, we’ll explore how Transkribus works, its benefits for genealogy research, and how you can get started using it.
I generated the text for this blog post using Google Gemini, a large language model, from a PDF file of a presentation I created about AI transcription tools. I manually edited and revised parts of it.
About Transkribus
Transkribus was created by scholars at the University of Innsbruck and has been further developed by READ-COOP since 2019. READ-COOP, which stands for “Recognition and Enrichment of Archival Documents Co-op,” is a non-profit organization with over 20,000 members, many from academia. Their mission is to make historical documents accessible to everyone, and Transkribus is a key tool in achieving that goal. The platform is designed to be user-friendly, even for those who are not tech-savvy, and it offers a range of features that make it a valuable asset for genealogists and historians alike.
Transcription Process
Transcribing documents in Transkribus is a straightforward process. I’ll show the process with the following deed:

First, you upload your PDF or image files (.jpg, .png) to the platform. Rotate sideways images before uploading them for transcription. When you import a PDF into Transkribus, the program separates each page into separate images. You can organize these files into collections, similar to folders on your computer.
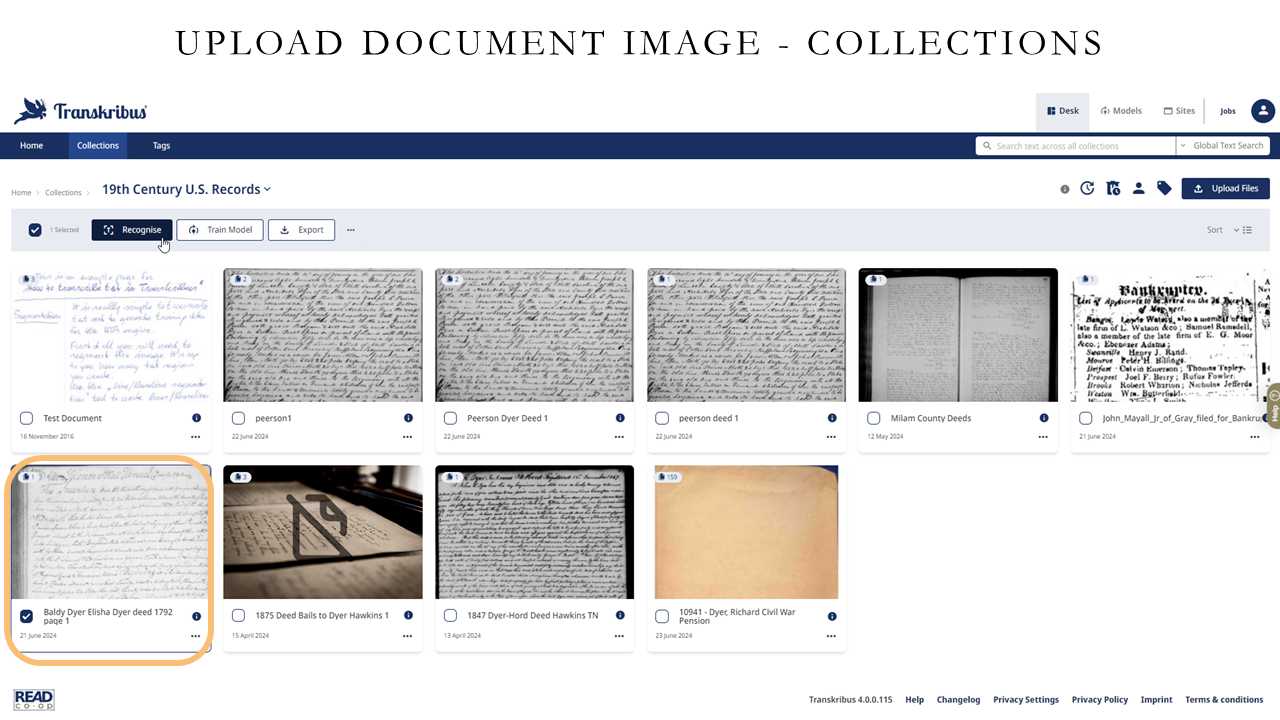
When you do the automatic text recognition, it first runs a layout recognition to find text regions, baselines, and words. If your document has a complex layout, such as tables or multiple columns, it’s recommended to run the layout recognition separately and manually correct any errors before proceeding. Examples of complex documents include tax records, inventories, and newspapers with many columns.
Next, you choose the appropriate language and model for your document. Transkribus offers a wide variety of models trained on different languages and time periods.
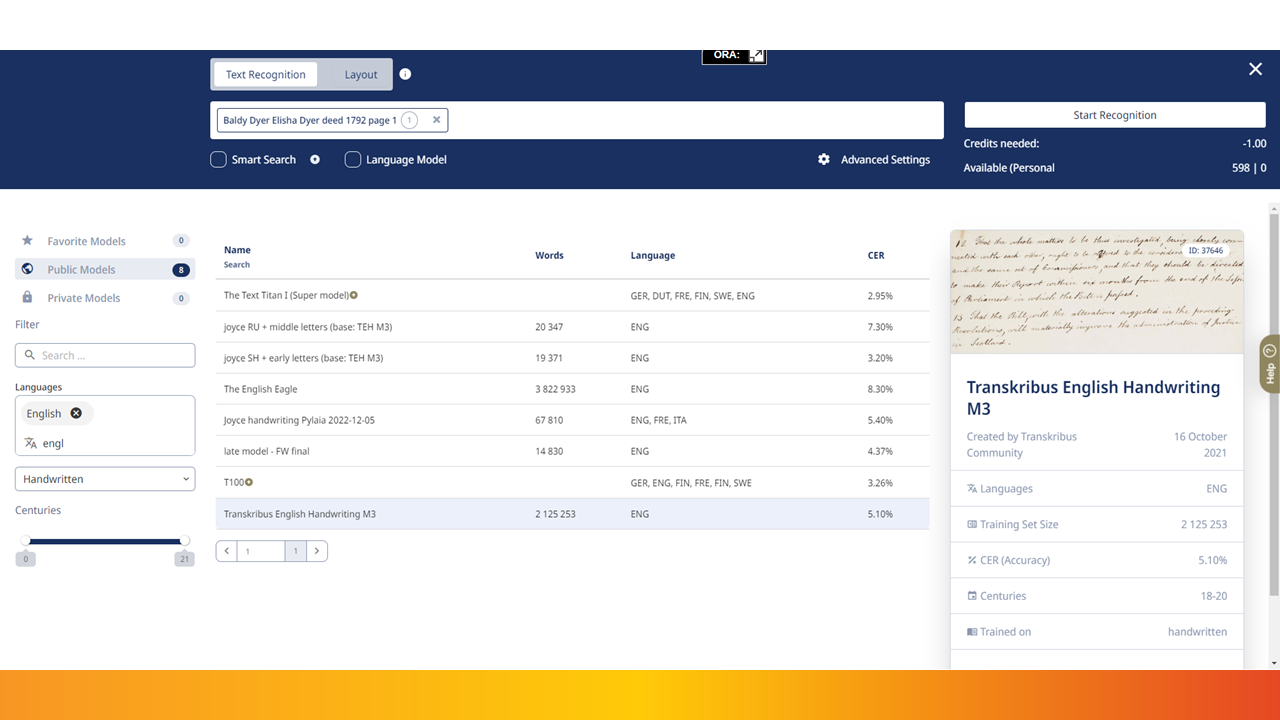
Once you’ve selected your model, you can start the text recognition process, which will automatically transcribe the text in your document. Recognize the text in several images at once, or one at a time; progress is saved in the jobs table.
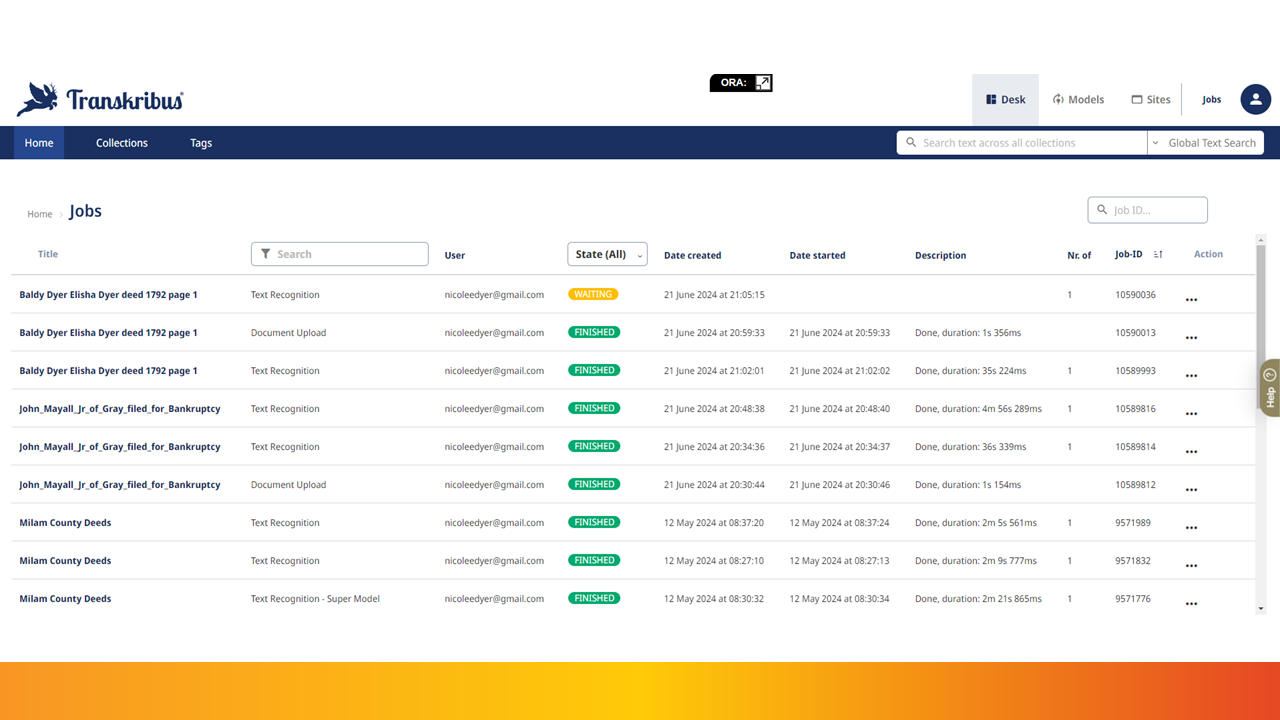
After the transcription is complete, you can review it and make any necessary corrections.

Finally, you can save, export, or search your transcribed document. There are several options for exporting, including copy/paste, or exporting as a PDF, Word file, text file, and so forth.
For 18th-century deeds, which often contain challenging handwriting, it’s crucial to select the right model and carefully review the transcription for accuracy. Transkribus provides tips and guidance on choosing the best model for your specific document type and language. The number of models increases often, but here is an overview as of May 2024:

Choosing the Right Model
Transkribus offers a wide array of pre-trained models to choose from. When selecting a model, consider the following factors:
- Type of text: Is your document handwritten, printed, or a mix of both?
- Language: What language is the document written in? Does it contain multiple languages?
- Training set size: How many words was the model trained on? Larger training sets generally lead to better accuracy.
- Time period: When was the document created? Models trained on documents from specific time periods may perform better on similar documents.
- Character Error Rate (CER): This indicates the percentage of characters transcribed incorrectly. Lower CERs mean higher accuracy.
By carefully considering these factors, you can choose the model that is most likely to produce an accurate transcription of your document. Transkribus provides detailed information about each model, including its training set size, time period, and CER, to help you make an informed decision.
Advanced Features
Transkribus offers several advanced features to enhance your transcription experience. One is the use of language models, which can significantly improve accuracy by predicting likely words and phrases based on the context of the text. This is particularly helpful for documents with challenging handwriting or faded ink. Another useful feature is Smart Search, which stores multiple alternatives for each word, allowing you to find a word even if it wasn’t transcribed correctly.
Transkribus also offers Super Models. These advanced models are based on transformer architecture, which excels at natural language processing. Super Models can handle multiple languages, old and new forms of language, and both handwritten and printed text. They are particularly useful for quickly creating ground truth data for training custom models. However, it’s important to note that Super Models require a subscription to use.
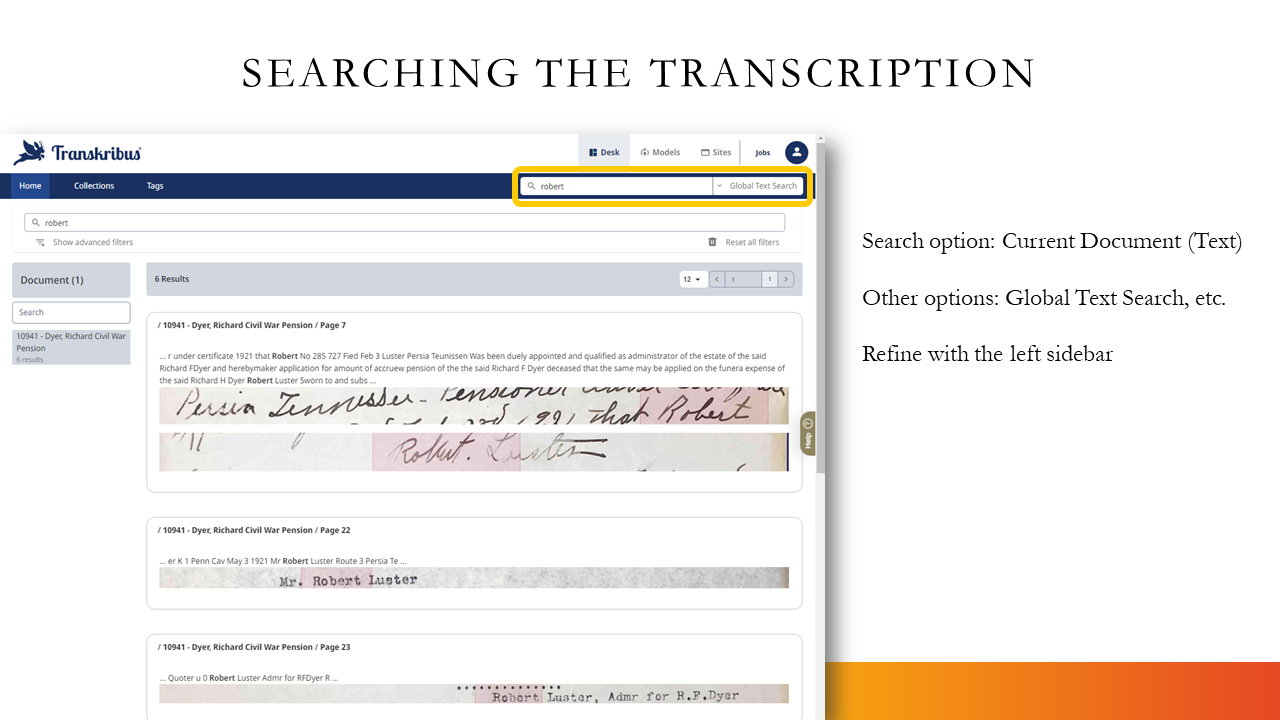
I upgraded from the free account to the “scholar” level for about $15 in order to test the Super Model’s transcription of a long U.S. Civil War Pension Application file for my husband’s 2nd-great-uncle, Richard Dyer. It had over 150 images. I hadn’t taken the time to transcribe the whole thing, because it was for a collateral relative, not a direct line relative. The number of images seemed daunting.


Transkribus did a great job with it, and I searched the completed automatic transcription for “Robert,” thinking it might mention Richard’s father, Robert. Instead, I found several mentions of Richard’s son, Robert Luster, who was born to a woman who was not Richard’s wife, but DNA and oral tradition provide evidence that they were father and son.
Training a Custom Model
If you have a large collection of documents with unique handwriting, penmanship, or language, you might consider training your own AI model in Transkribus. This can lead to significant improvements in accuracy compared to using pre-trained models. To train a custom model, you’ll need to manually transcribe 25-75 pages of your documents (or more if the documents are diverse). The accurate transcriptions you provide in these 25-75 pages become the ground truth for your custom model. Ground truth is the target for training an AI model. You can speed up this process by using a similar base model or Super Model as a starting point and then correcting the transcriptions manually. To ensure the best possible results, it’s crucial to make sure your training data is accurate and consistent. You can also check baselines and add more data to further improve the Character Error Rate (CER) of your model.
Use textual tags to enhance your transcriptions by tagging specific words like abbreviations, places, and people, and adding additional attributes. Enable textual tags by clicking on the tag icon. Select text, then use keyboard shortcuts to apply tags (e.g., superscript CTRL + .).
Transkribus for Printed Documents
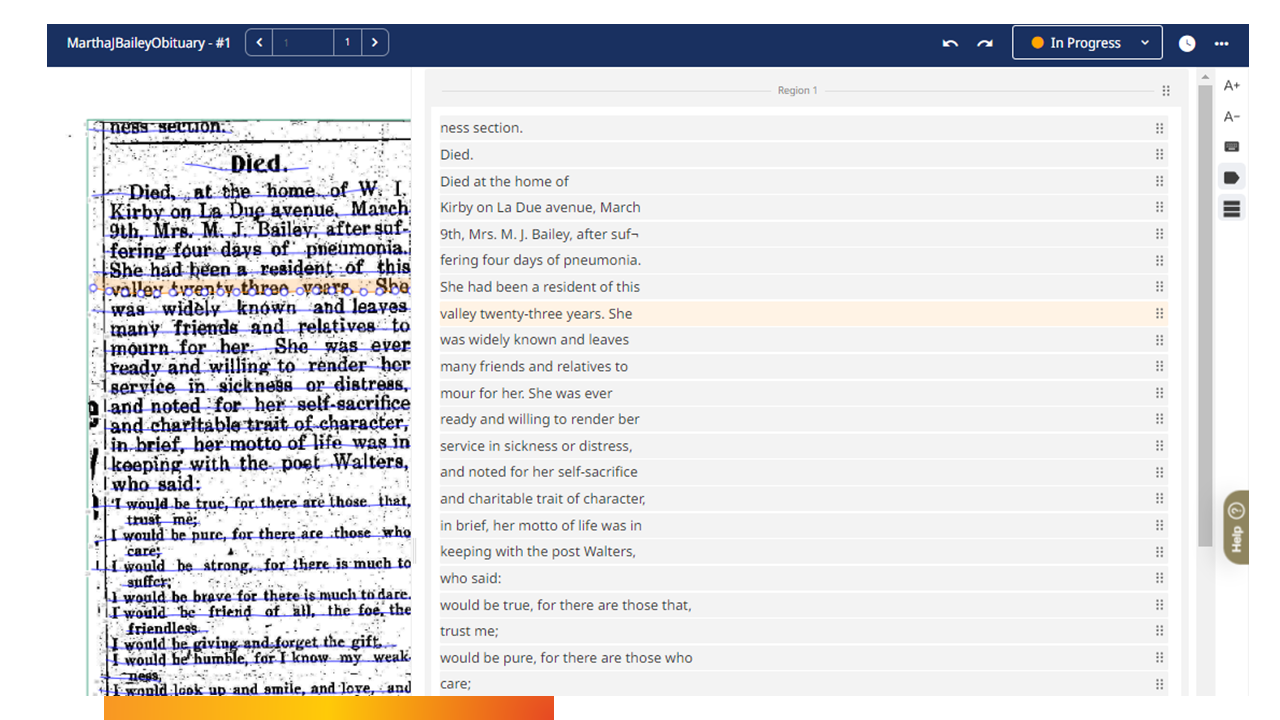
While Transkribus is primarily known for its handwritten text recognition capabilities, it also excels at transcribing printed documents. In fact, it outperforms traditional Optical Character Recognition (OCR) software, especially when dealing with faded or problematic images. For example, Transkribus can accurately transcribe an obituary with faded text or a challenging newspaper article from the 1800s.
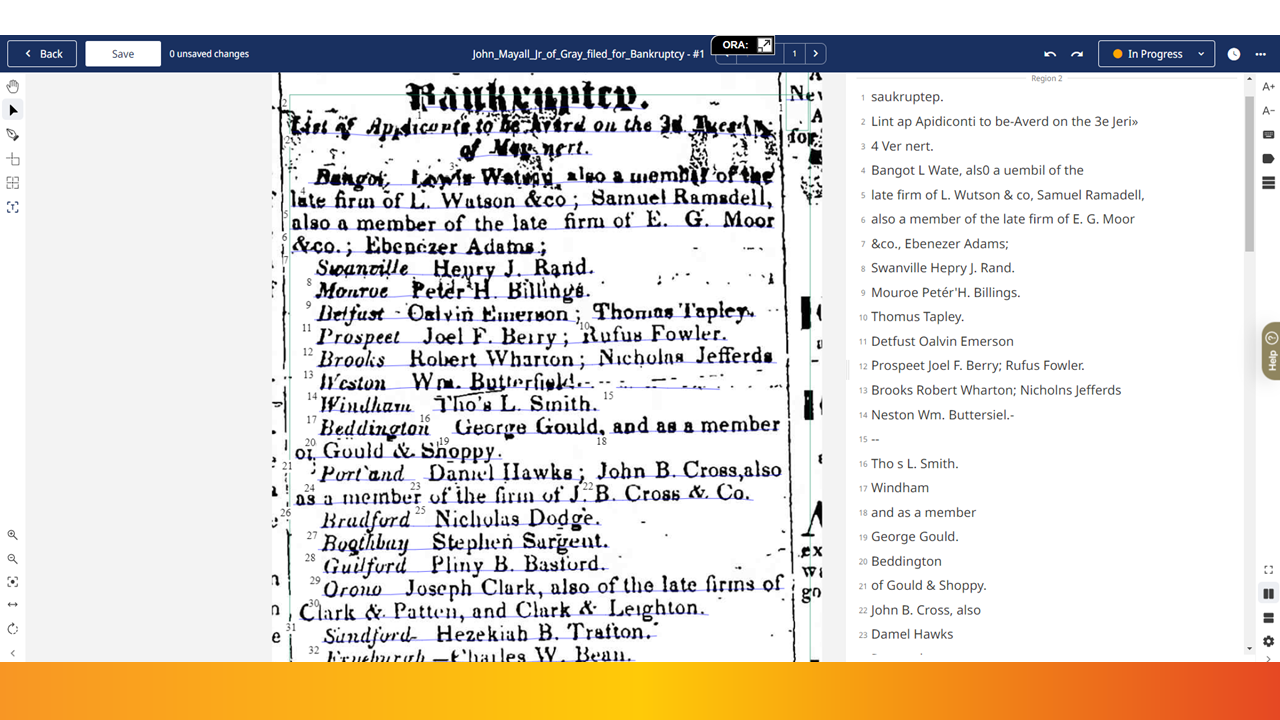
If you have an illegible sentence, like the start of this bankruptcy article, the model will have a hard time reading it. You can type directly into the transcription area to correct it, or you can try copying/pasting the transcription into a LLM like ChatGPT to ask for suggestions on fixing it. This works well for deeds and will with narrative and lots of common boilerplate phrases; but for this bankruptcy article, it would be easier to just correct it yourself in Transkribus.
Tips and Tricks
Here are some additional tips and tricks to get the most out of Transkribus:
- Fixing Regions and Lines: If the automatic layout recognition doesn’t accurately identify the text regions and lines in your document, you can manually edit them using the three-dots menu or keyboard shortcuts. This will ensure that the transcription process runs smoothly and produces accurate results.
- Handling Mixed Text: For documents containing both handwritten and printed text, such as U.S. Civil War pension applications, Transkribus’s Super Models are the best option. These models are specifically designed to handle mixed text and can significantly improve accuracy compared to using separate models for handwritten and printed text.
- Searching within Transcriptions: Once you’ve transcribed a document, you can easily search for specific words or phrases using the search function. This can be a valuable tool for genealogists who are looking for specific names, dates, or locations within a large collection of documents.
Additional Resources
To learn more about Transkribus and its features, you can explore the following resources:
- Transkribus Help Center: https://help.transkribus.org/
- READ-COOP Website: https://readcoop.eu/
- Transkribus YouTube Channel: https://www.youtube.com/@transkribus
These resources offer tutorials, FAQs, and other helpful information to guide you through the transcription process and make the most of Transkribus’s capabilities.
Conclusion
Transkribus can become a significant time-saver as you are transcribing and searching through documents. Its AI-powered transcription capabilities can help you find needed evidence in long image files. I encourage you to give Transkribus a try and see how it can aid your research process.
Learn More
Learn more about using AI tools in our hands-on workshop, Research Like a Pro with AI.









2 Comments
Leave your reply.