Updated 24 February 2022
When working on a case involving DNA test results, it may feel like you look at hundreds of DNA match pages, reports, family trees, and shared match lists each time you sit down to research. Do you want a better way to keep track of all the sources you consult in a DNA research project? It’s time to take your research log to the next level.
In the Research Like a Pro with DNA series, we’ve talked about several steps for undertaking a focused research project about a specific research subject. Now we are ready to discuss step 9 – using a DNA research log to keep track of genetic genealogy searches.
Step 1 Take a DNA Test: Which DNA Test Should I Take? and DNA-Recommended Testing Strategy
Step 2 Assess: Understanding and Using Your DNA Results – 4 Simple Steps
Step 3 Organize: Seeing the Big Picture: 3 Ways to Chart Your DNA Matches
Step 4 Research Objective: What Do You Want to Know? 3 Steps to Focus Your DNA Research
Step 5 Analyze your Sources: DNA Sources, Information, and Evidence: Sorting it All Out
Step 6 Locality Research: Where in the World Has My DNA Traveled? DNA and Locality Research
Step 7 Research Planning: Genealogy Research Planning with DNA
Methodology and Tools to use as you plan your research:
– Charts for Understanding DNA Inheritance
– Clustering or Creating Genetic Networks
– Pedigree Triangulation
– Chromosome Browsers
– Segment Triangulation
– Chromosome Mapping
– DNA Gedcom
Step 8 Source Citations: DNA Source Citations
Step 9 Research Logs: DNA Research Logs: how to keep Track of Genetic Genealogy Searches – You Are Here
Step 10 Report Writing: DNA Research Reports – the Ultimate Finish
Step 11 What’s Next? Continue Your Research & Writing, Productivity, and Education
What is a Research Log?
A traditional genealogy research log is used to track sources searched, what was found, and include information to get to those sources again – call numbers, repositories, URLs, source citations, and document numbers.
Genealogists keep track of where they looked for information in their research log and whether or not they found anything. If you look in a source and don’t find the information you were seeking, note the negative search in your log. This practice helps you avoid repeating searches. The entries in your research log are a reminder of where you left off and provide a convenient starting point for the next research session.
As researchers incorporate DNA sources into their research, they introduce a substantial amount of data to their pool of information. It will be critical to the success of your research project to keep track of all the DNA sources consulted in your research log. Logging the results of your searches helps you make connections between the pieces of data.
Many of the DNA matches researchers consult do not yield a discovery of the most recent common ancestor immediately. Just like negative searches in a census database, we note the negative results of viewing a DNA match page when nothing is discovered. Eventually, we may need to return to this DNA match and dig deeper to determine the connection. Noting all clues from the DNA match, like surnames, shared matches, and common locations in the family tree, could prove useful in the future if captured in your log. Without a research log, you will probably forget the information you viewed and it won’t be available to you to correlate and form conclusions.
Adding DNA Sources to a Research Log
DNA Sources are people. Genetic genealogists don’t actually examine a person’s DNA, they view reports made by testing companies. (Read more about this concept in Robin’s post – DNA Sources, Information, and Evidence: Sorting it All Out.) These reports typically include a list of DNA matches. DNA matches are key elements of a DNA research log.
How many research logs are needed? Some researchers create a separate research log for each research subject or ancestral couple. I create a separate research log for each objective. When performing research for a client, I typically create a new research log for each project. If the client renews and wants to continue researching the same objective, sometimes I will continue with the same log. Keeping the research log limited to a focused objective helps keep the size of the log manageable.
When adding DNA sources to my research log, I only include the matches who are relevant to the subject of my research objective. To include all the matches in a match list would obscure the information I’m trying to draw out.
DNA Matches
Each DNA match may require several steps to determine how they are related to the test taker. This means there may be several entries in a research log relating to one DNA match. Here are some possible entries for my DNA match John:
– Match page for John
– Family tree attached to John’s results
– Ethnicity report comparing my ethnicity to John’s
– Shared match report showing matches in common on my match list and John’s match list
– Searches in additional published family trees to find John’s ancestors
– Searches in other records groups to find John’s ancestors
Each of these will require separate source citations and will give different notes to write in the results section of the entry. For the match page with John, you might note in the results column that the shared cM seems to indicate a 2-3rd cousin relationship. You can also add the link to the match page for John in that entry, and the link to the family tree in John’s family tree entry.
Many genetic genealogists utilize Ancestry.com or other tree building and hinting services to build quick trees for DNA matches (which are marked private and unsearchable since they are not properly proven until after a hypothesized connection is found). If you do this, your quick tree may include records attached to individual’s profiles which could replace some of the searches recorded in a research log. An entry in your log could be revised to include a link to the quick tree and a summary of this method and what you learned in the notes section.
DNA Tools and Methods
To get the most out of your DNA research, it’s imperative to log your activities. During a DNA research session, you may use several tools and reports to help you understand DNA information. Research log entries may include all kinds of reports and methods from DNA companies and third party tools, including:
– Autocluster reports
– Chromosome browser reports
– Chromosome mapping
– Leeds method results
– Segment triangulation data
– Surname project
– One-to-one DNA comparison
– Segment search
– Ancestry Thrulines
– MyHeritage Theories of Relativity
– Haplogroup report
– Quick tree
– What are the Odds tool (WATO)
DNA Instructional Material
Your research log may also include entries to DNA instructional material that you may need to cite in your report that gives meaning to the data. The following entries could be created:
– Informational articles at DNA testing company websites
– Articles from the ISOGG Wiki
– Books about genetic genealogy
– Blogs or website articles by genetic genealogists
– Shared cM project
– Genetic studies
Steps for Using a DNA Research Log
Now that we’ve covered what belongs in a DNA research log, let’s review the steps for using one:
1. Create a separate research log for each objective. A focused research objective asks an answerable question about an identifiable research subject. For example, “Who were the parents of John Robert Dyer, born about 1813 in Tennessee, died in 1879 in Hawkins, Tennessee, and married Barsheba Tharp?” Your research log should not include all the DNA matches of a test taker, only those found to be pertinent to the research objective.
2. Follow your research plan and add entries to your log for each result from traditional genealogy sources you search. Also include each result from DNA sources you consult. Include DNA tools and other methods you try and what you learn from them (i.e. Leeds Method, visual phasing, segment searches).
3. Create source citations for each entry. (See Robin’s blog post here for guidance: DNA Source Citations)
4. Include links for each entry, where possible. The links may be to a match page at a testing company, a profile at an online family tree, or a shared match list. You might also want to link to the files on your computer that contain auto-cluster reports, screenshots of match pages, and so forth.
5. Write notes about what you found in the results section.
6. Write your ideas about what can be done next in an additional comments column. Note possible connections between other entries.
Components of a DNA Research Log
In a traditional research log, you may only need one sheet in a spreadsheet. However, in a DNA research project, multiple sheets will help you stay more organized. A correspondence log, a research log, and additional sheets for DNA comparisons can be useful. Additional sheets could include:
– Leeds method worksheet
– Y-DNA STR marker comparison
– Matrix comparing multiple test takers with each other
– Matches from an additional test taker whose DNA test you administer or whose DNA match list has been shared with you (if related to the objective)
– Shared match comparisons
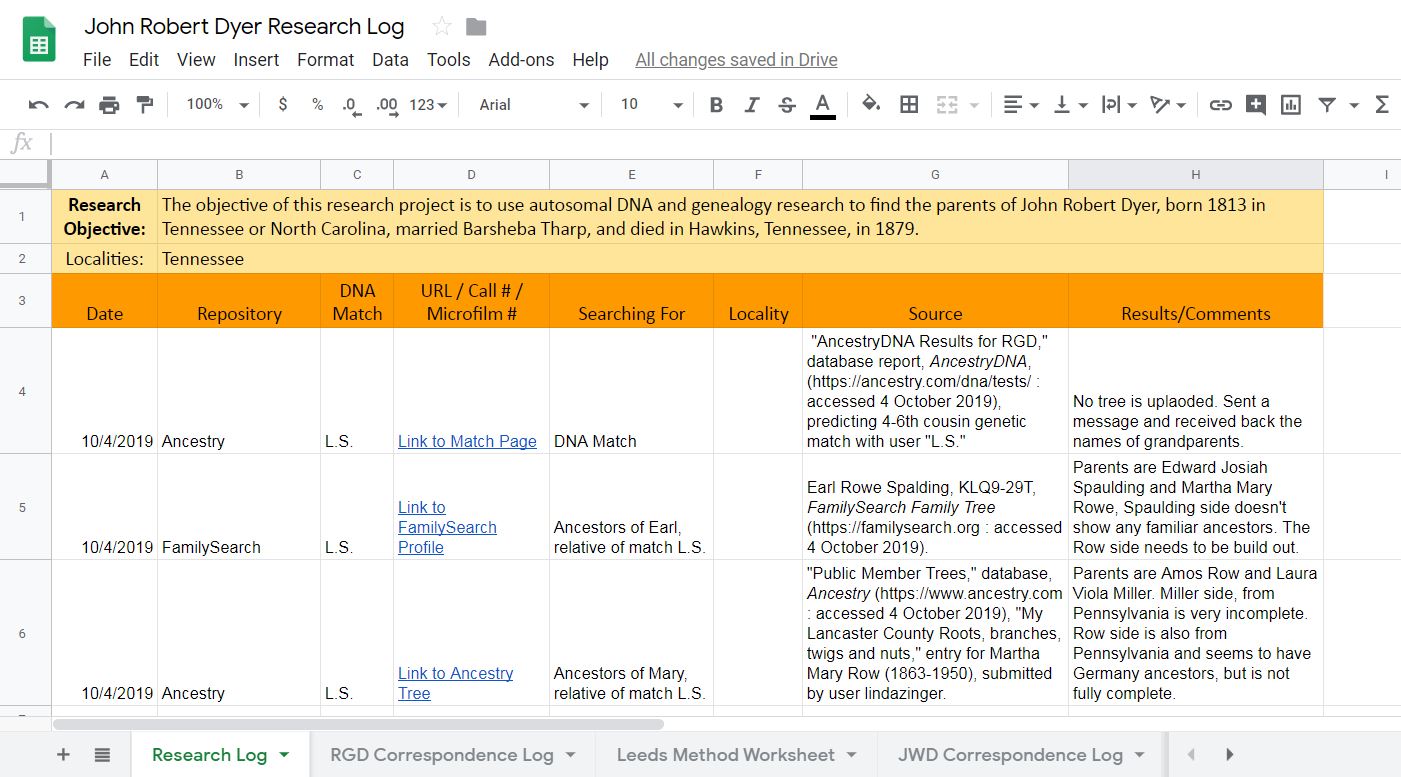
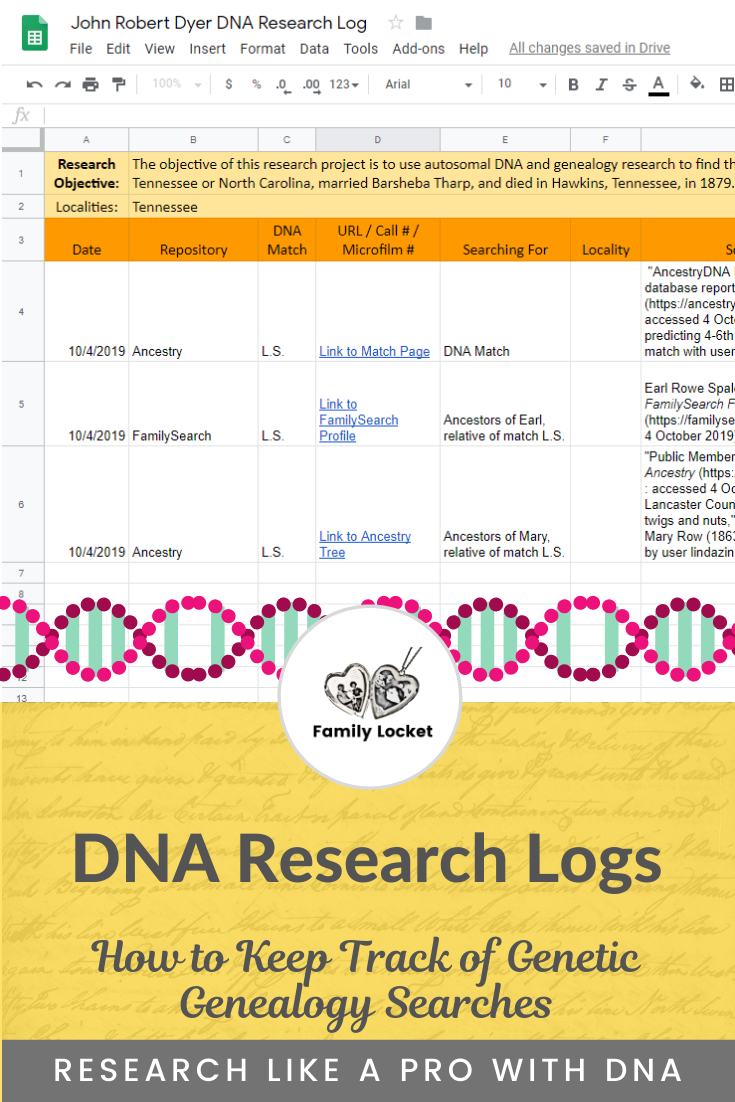
Figure 1
In figure 1, you’ll see multiple tabs at the bottom of the spreadsheet including the research log, a correspondence log for two test takers, and a Leeds method worksheet. The correspondence log includes more data about each match, the amount of shared cM, when a message was sent, and so forth. An example of the correspondence log is shown in figure 2. Column B with the match name has been hidden.
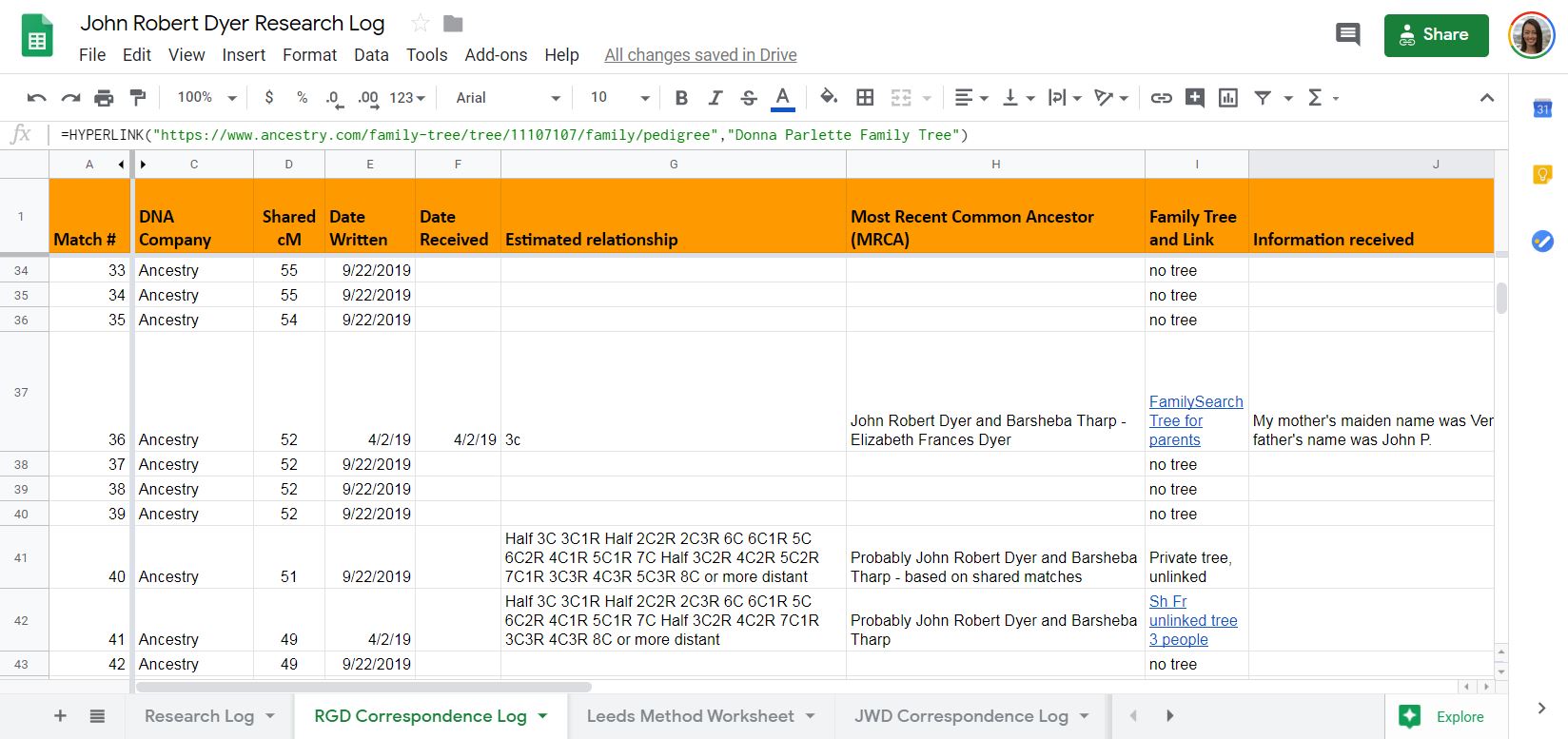
Figure 2
Column Headings
Here are the headings that I’m using in my DNA research log example in figure 1:
– Date of the search
– Repository/website
– Match name
– URL
– Description of what I’m searching for
– Locality (for documents/records in a specific place)
– Source citation
– Results/comments
For the correspondence log, some possible column headings as shown in figure 2 are:
– Match name and link to match page
– DNA company
– Shared cM
– Date written and date received
– Estimated relationship
– Most recent common ancestor if known, or guess
– Family tree and link
– Information received from correspondence with the match
– Next steps
– Additional contact information
Tools for Creating Research Logs
I have used Google Sheets, Excel, and Airtable to create my research logs. They all work well, but Airtable is the most powerful option, because it’s more of a database, with records from one sheet linked to the entries in another sheet.
Google Sheets
In figures 1-2, I used Google Sheets to create a spreadsheet for my DNA research log. It’s handy to be able to use my research log from all my devices and have the changes synced instantly. Google Sheets is also unparalleled for collaborating with others.
As I have mentioned, I like to add links to applicable webpages in my log so I can easily return them. Here’s how I do that without showing the whole URL, which is sometimes very long:
1. Select a cell.
2. Type a simple description of the link, i.e. FamilySearch profile of John Robert Dyer
3. While the cell is still selected, use the keyboard shortcut Ctrl + K
4. In the link editing box that pops up, paste the URL of the webpage you want to link to in the link section. Click Apply.
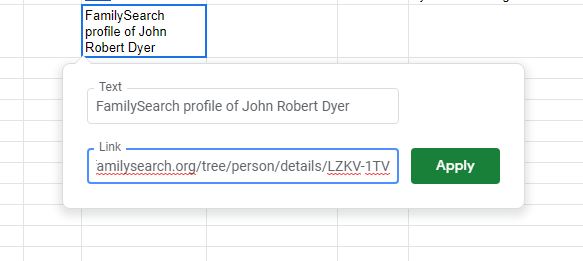 Now, your text is linked to the URL. Both the text and the link are saved within the cell.
Now, your text is linked to the URL. Both the text and the link are saved within the cell.
Excel
Microsoft Excel is a powerful tool for research logs. It has more functionality than Google Sheets. Lisa Stokes, AG, has a great series of tutorials about using Excel for genealogy research logs on her YouTube channel here: Lisa Stokes Heritage Research YouTube Channel
Airtable
Airtable is a web based program for creating spreadsheets. The way Airtable is described on their homepage is “part spreadsheet, part database, and entirely flexible.” The features of Airtable work incredibly well for a DNA research log. Read more about Airtable for Research Logs in my other article here.

One of the pain points I was having with my DNA research log in Google Sheets was the inability to link entries from my correspondence log sheet to my research log sheet. I didn’t want to enter the match name, # of cMs shared, and URLs all again. Duplicate data entry isn’t fun.
With Airtable, you can link related content from one sheet to another. Linking records between tables is exactly what I wanted to do, and exactly what Airtable does! This graphic from the Airtable product feature page shows how linking works.

Another helpful feature is the ability to create different field types. Numbers, dates, long text, short text, multiple choice from a list of options, checkboxes, URLs, and even attachments. This is great for adding attachments like screenshots of match pages, cluster reports, and other files. The files are uploaded directly to Airtable.
In Airtable, the spreadsheet is called a base (short for database).

Each sheet within a base is called a table. When I first started with Airtable, I created a base for my John Robert Dyer research project, with separate tables for my correspondence log and research log. Later, I decided I wanted to add tables for matches of R and matches of J, two of the test takers whose results I’m using.

When I started doing research on some of these matches to determine a common ancestor, I kept track in the research log table. I added a column for which match I was researching about, and then included the usual columns for a research log. Here’s where I typically felt annoyed about duplicate data entry in a regular research log. I wanted to see the match’s name, have a link to the match page at Ancestry, and see the # of shared cMs. But I didn’t want to type it in again, since it was already in my correspondence log.
That’s the beauty of Airtable. Instead of typing the match name again, and pasting a link to the AncestryDNA match page, and including the shared cM, you add a column to your research log that is a link to the entry for that DNA Match in your correspondence log table. You do this by selecting the column’s field type to be “Link to another record” – then choose the table that you want to link records from within that same base – the correspondence log. You can then start typing one of the DNA Match names, and a list of entries that match from that correspondence log pops up.
The first column of each table is the “primary field.” The primary field in my correspondence log is the match name, so that’s how you link the entry in the correspondence log to the entries in your research log that go with that match.
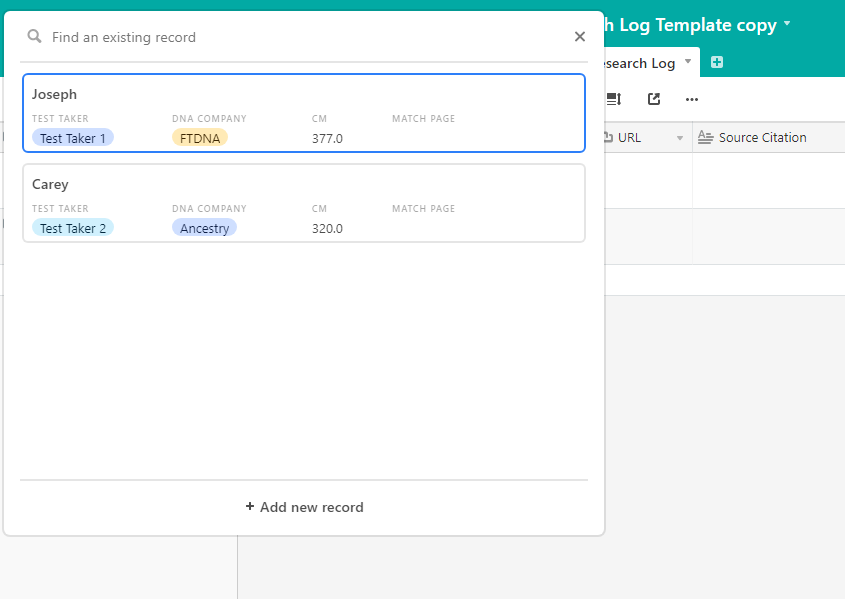
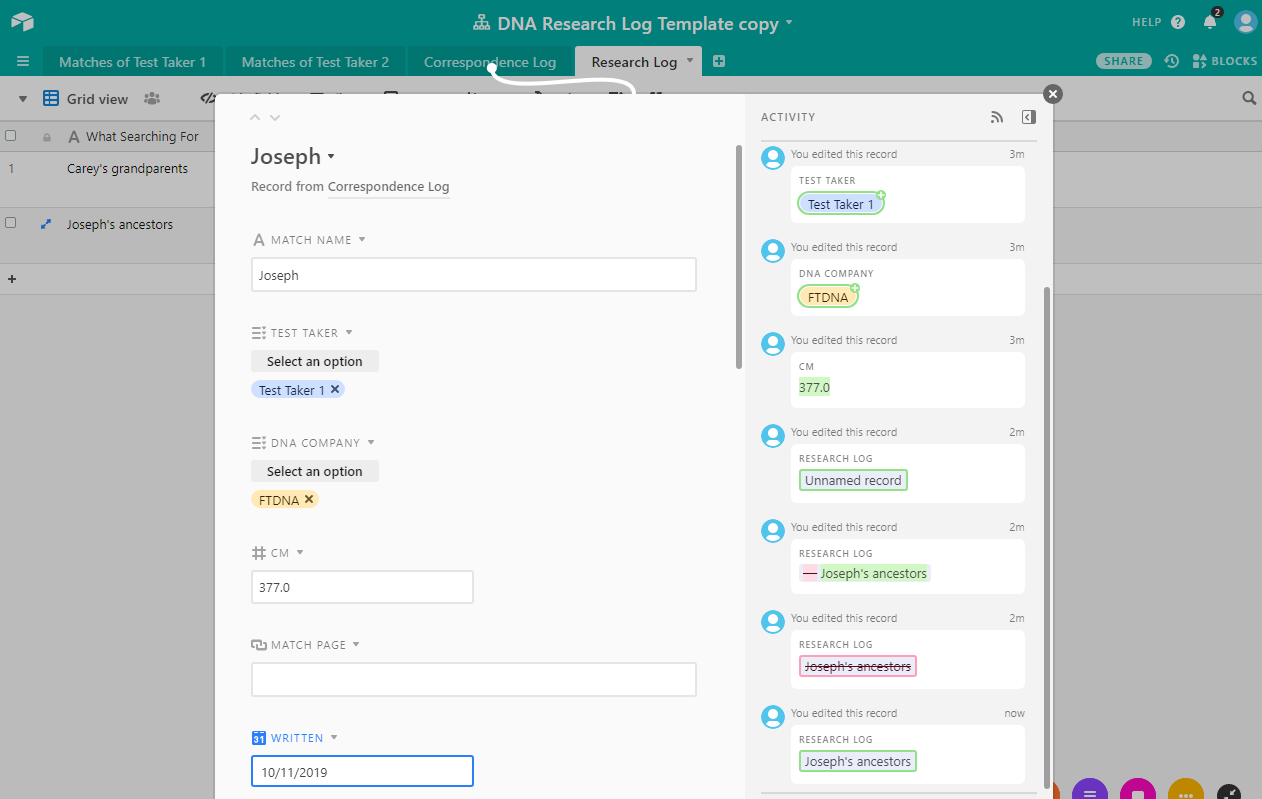
Click on the match name from that column expands the record so I can view all the notes, messages, shared cM, and other info related to that record in the correspondence log. Hooray! All the information I need in one place.
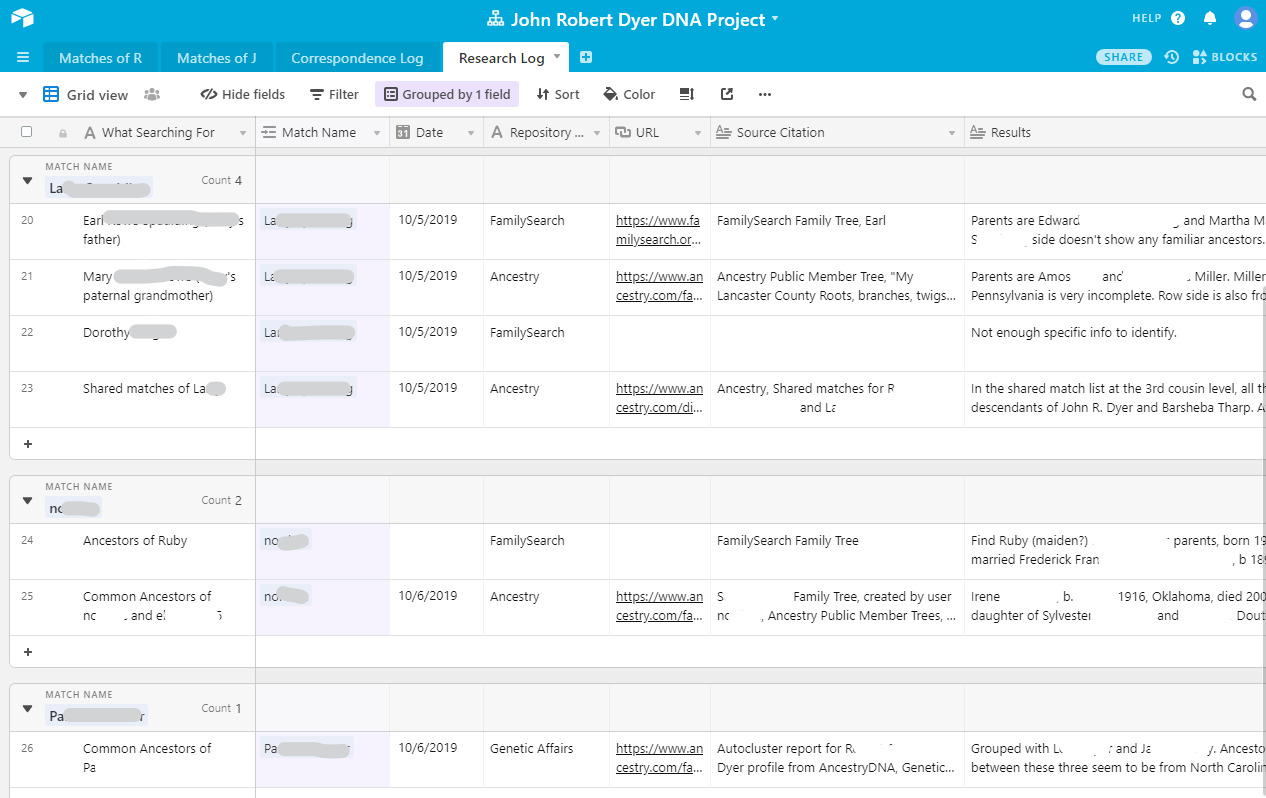
Another helpful feature of Airtable is the ability to group records. In my research log table, I wanted to group all my searches by which match the search was for. I logged several searches for some of the matches, trying to find their ancestors in published family trees, the social security death index, obituaries, etc. In the screenshot below, I have privatized many of the names. You can see how each grouping represents one match name and the searches done about the match and their ancestry.
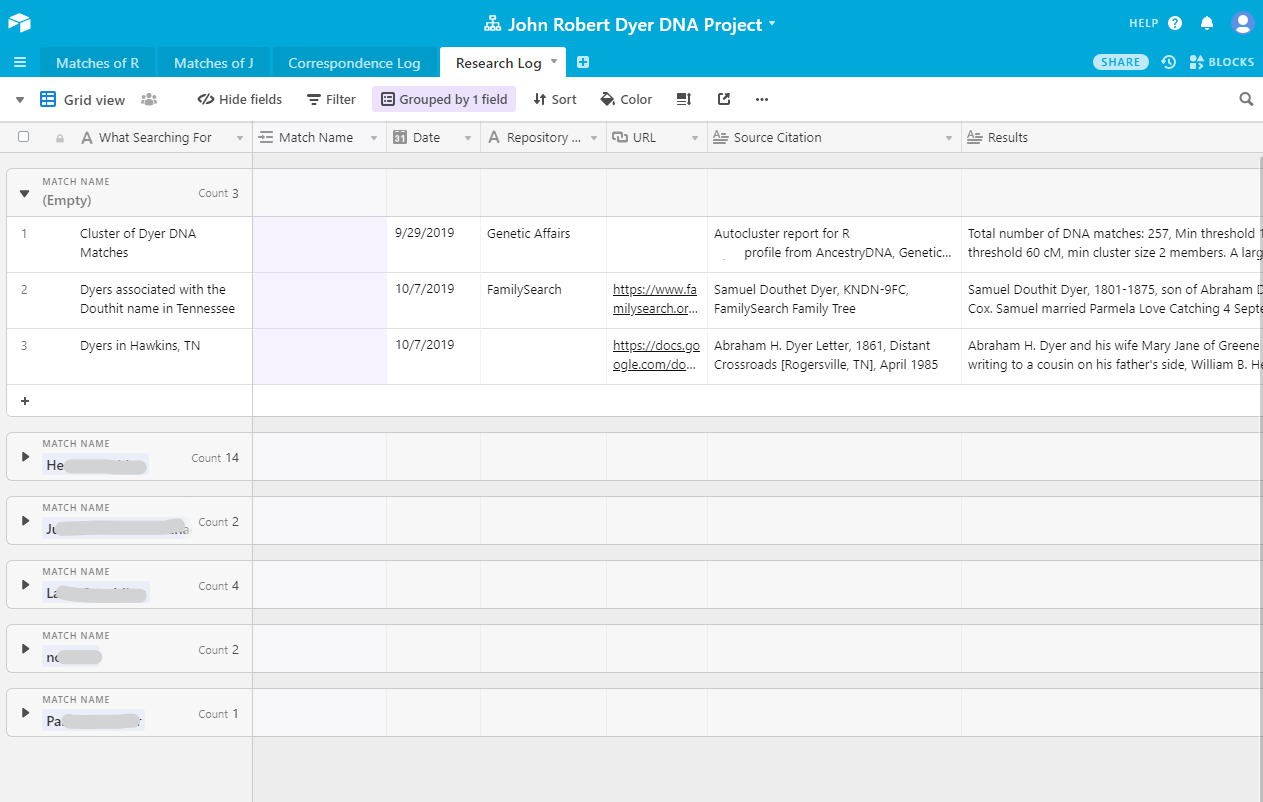
Airtable even allows you to collapse and expand the groups, so I don’t have to see all the searches for each match unless I expand them. Here is a screenshot showing the match groupings collapsed. The first grouping I didn’t collapse. These are the searches done that don’t apply to one specific match.
To learn more about how to use Airtable, check out their website and their support page which has videos and guides. Airtable is free to use with a limit on how many records you can have in each base. You can upgrade for premium features. So far I have not needed to upgrade.
To see my most recent Airtable base templates for keeping track of DNA matches, go to my Airtable Universe page and scroll to the bottom for the newest base. You can then duplicate the base, delete the example rows of data, and begin tracking your own matches.
Start Keeping Track
Whichever tool you use to keep track of your DNA sources and searches, start now! It makes a big difference to see what work I’ve already done and to know what still needs work. I’m also seeing more connections between the data than before. It feels empowering to know that all the work I’ve done on this objective is captured in a way that makes sense to me and that I can use.
Best of luck in your genetic genealogy research!
————
Read more about research logs here:
Research Logs: The Key to Organizing Your Family History by Diana Elder, AG at FamilyLocket.com
RLP 8: Research Logs – Podcast episode with Diana and Nicole
Research Like a Pro, Part 5: Where Did You Look and What Did You Find? – by Diana Elder, AG at FamilyLocket.com
Save to Pinterest









5 Comments
Leave your reply.